
編輯: BlockBeats
自2023 年初以來,人工智慧(AI)已成為科技領域的新高地,尤其是在ChatGPT 的推動下,AI 技術的熱潮在全球範圍內迅速蔓延。這場趨勢不僅引發了一場涉及全球科技巨頭的「AI 軍備競賽」,更是重塑了科技產業的發展軌跡。對於Web3 產業的從業人員來說,AI 與Web3 的結合不再是遙遠的概念,而是一個明確且可行的發展方向。
在過去的一年中,「Web3 + AI」的概念迅速成為行業熱詞。在這個過程中,一個產業共識逐漸形成:「區塊鏈解決生產關係問題,AI 解決生產力問題」。這不僅是兩大科技領域融合的精準概述,也預示著Web3 與AI 結合將成為未來科技發展的重要趨勢。在Binance Labs 公佈的第六季12 個全球孵化計畫項目中,QnA3 作為一款「AI 驅動的Web3 知識平台和投研交易工具」,是其中頗具代表性的與AI 緊密結合的Web3 DApp。
BlockBeats 分析了QnA3 的發展情況,並對各個階段的技術路徑和理論進行了整理。
QnA3 的發展路徑
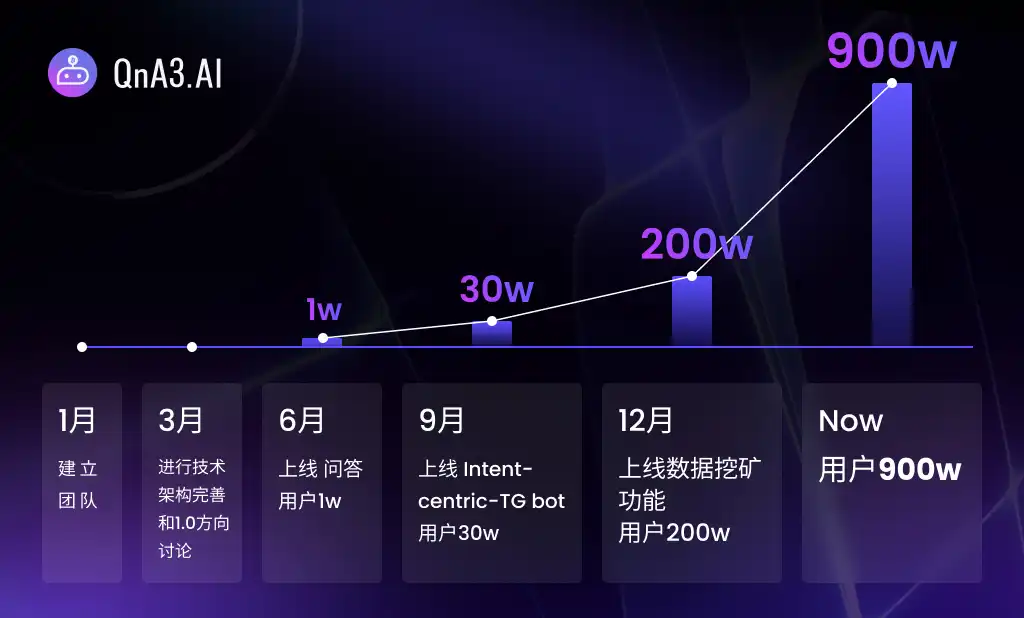
QnA3 團隊成立於2023 年1 月,在短短一年內實現了其產品從0 到1 的巨大蛻變:6 月,QnA3 上線問答功能,用戶量突破1 萬;9 月,QnA3 上線以意圖為中心的Telegram 機器人,用戶量突破30 萬;12 月,QnA3 上線資料挖礦功能,QnA3 日活躍用戶數霸榜BNB Chain No.1 超過半個月時間,用戶量突破200 萬。如今,QnA3 用戶數已飆升至900 萬。
QnA3 的核心定位:Web3 世界居民必備的AI Agent
根據官方的介紹,QnA3 是Web3 世界居民必備的AI Agent,協助使用者進行Web3 化全生命週期的全場景管理。
1)資訊管理AI+Research =“RAG”
QnA3 是Web3 領域中AI+搜尋的領跑者和全能型選手。
基於GPT 微調模型等通用智能生成能力及Google、微軟Bing 等搜尋引擎構建,QnA3 對比ChatGPT 等生成式AI 具有專業數據和專有知識的壁壘,信息時效性強、可追溯信源並有效減少幻覺。比較Google等傳統搜尋引擎,QnA3 答案沒有資訊冗餘、準確可信,問題可拆解,答案可被回饋。
依託於對LLM 的理解和Pre Train(預訓練)、Post Train(訓練後),Scaling Up(可擴展性),Inference(推理)的豐富經驗[1],QnA3 將LLM 與搜尋有機結合,優秀的產品力、工程化能力和快速迭代能力使QnA3 後發先至,在眾多前行者中突圍並穩固領跑者身份。資訊管理功能已經可以滿足概念問題,即時問題,推理問題,市場分析問題和交易問題等不同場景的需求。
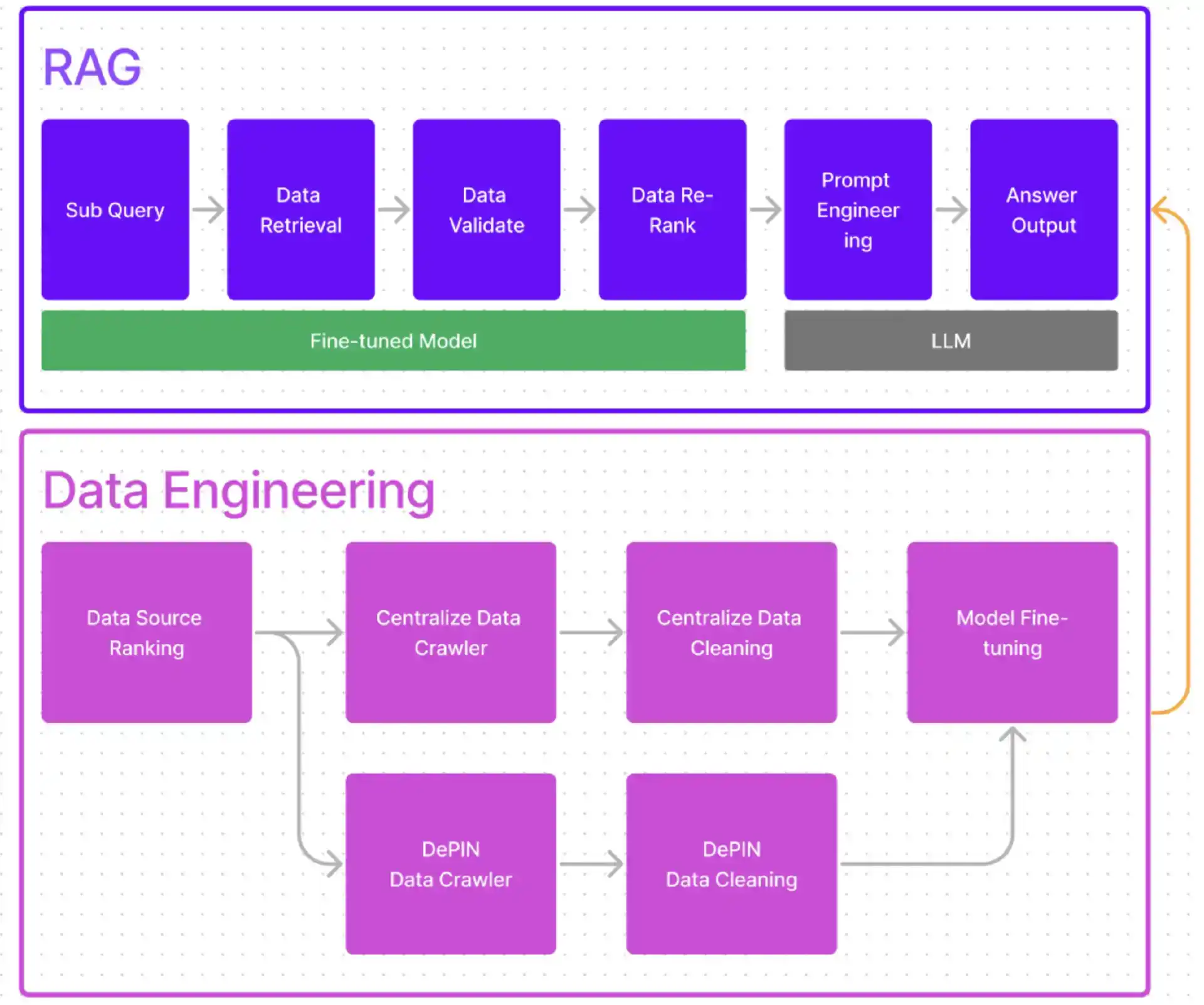
實現後發先至的核心技術原理:將RAG(Retrieval Augmented Generation,檢索增強生成)技術發揮到極致,同時滿足「Web3 知識專業性」、「高即時性」和「問答內容強關聯性」。
在專案成立早期,QnA3 分析了以ChatGPT 為代表的通用大模型,認為LLM 主要的問題之一為內容時效性差(2023 年初OpenAI 發布的ChatGPT3.5 版本,資料範圍只能統計到21 年9 月),同時存在缺乏索引帶來的潛在幻覺風險。
本質上來說,LLM 無法產生訓練資料與語料庫以外的內容,也無法為產生內容提供精確索引和參考依據。 QnA3 採取的方式是學習Meta。 2020 年,Meta 研究人員透過引入RAG 把與問題相關的事實交給LLM 加工和學習,不僅結合了生成模型的先驗知識,也汲取了檢索模型的即時性和內容的豐富性。
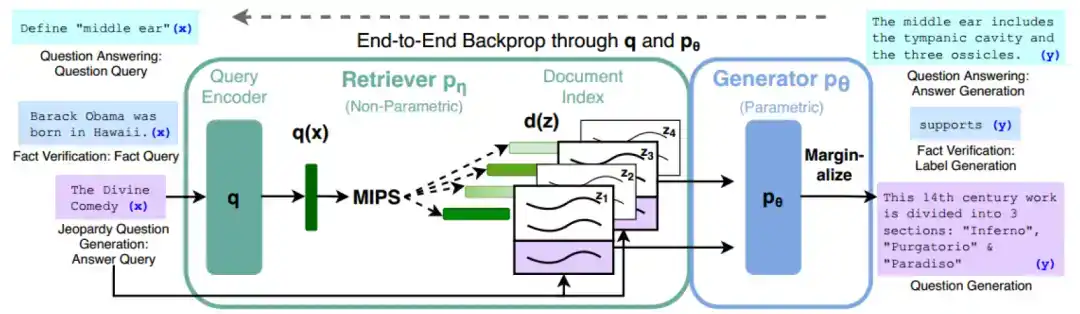
檢索增強生成(RAG)技術原理[2]
檢索增強生成技術(RAG)包含檢索、產生兩個環節。
檢索系統(Retriever):檢索環節包含需求編碼器(Query Encoder)和文件索引(Document Index)。使用兩個不同的BERT 模型將需求q 與文檔z 分別編碼為q(x) 和d(z),進而使用最大內積搜尋演算法取得內積最大的文檔,將其與需求共同輸入生成部分。
生成系統(Generator):在此環節,生成器根據擷取器總結輸出最終答案。大模型會根據輸入預測下一個字的出現機率,並產生機率最大的單字。共有兩種方式計算生成機率:1)RAG-Sequence:使用同一個文檔預測,先確定文檔再計算候選詞機率;2)RAG-Token:使用不同文檔預測,每個候選詞的機率為所有文檔的條件機率之和。
QnA3 以RAG 作為AI+Research 的核心技術,憑藉團隊超過十年的數據經驗,以數據的理解和應用能力為基礎,在檢索能力、響應速度和數據源質量三項重要指標始終保持領先地位;採用RAG 融合外部知識庫與模型先驗知識,外部知識庫豐富且易於更新的資料有效彌補了大模型資料滯後、伴隨幻覺的劣勢。
2)資產管理AI+Trading =「具備Intent-Centric 的AI Agent」
交易是所有Web3 世界居民繞不開的環節。 QnA3 基於Paradiam 提出的「以意圖為中心」(intent-centric)的概念,結合使用者與AI 互動的問題,得到了幾個洞見:
1)使用者意圖的建立是逐步的,但是最初的意圖是模糊的,甚至是不準確的。
2)意圖的準確與否直接決定了使用者最終的體驗,而這很大程度由意圖識別來決定。
3)最終配合使用者的實作路徑越簡單快速安全越好。
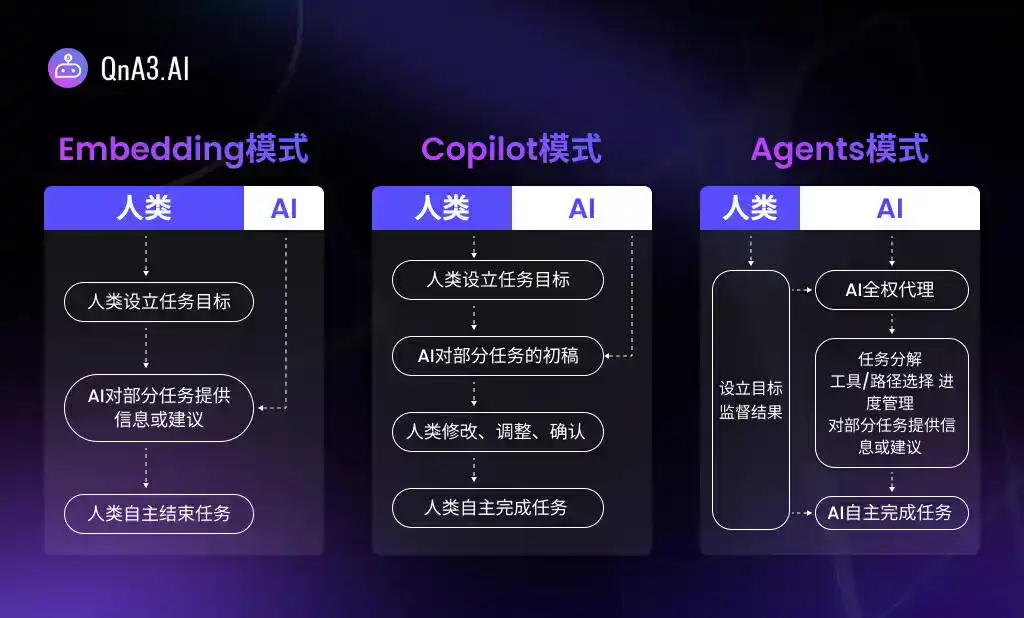
主流科學界將人類與AI 的合作由初級到高級分為Embedding、Copilot 和Agents 三種模式。在Copilot 模式下,工作由人類主導、部分任務初稿由AI 協助完成,而在Agents 模式中,AI 充分發揮「智能」,可以表現出更強的任務拆分、工具選擇和進度控制能力,人類只需設立目標、提供資源並監督結果,工作的具體展開可全權交由AI 代理,即「以意圖為中心」(intent-centric)。
對「以意圖為中心」(intent-centric)實踐的系統框架,OpenAI 安全團隊負責人Lilian Weng 曾提出,在基於大模型的自主代理系統中,LLM 作為核心控制器,充當AI Agent 的大腦,具備推理能力,而其他三個關鍵組件Planning、Memory 和Tool Use 將賦予LLM 執行更複雜任務的能力[3]。這與QnA3 在實現Intent-Centric 時設計AI Agent 的思路不謀而合[4]。

在完成資訊的管理工作後,QnA3 上線的代幣技術面分析與交易功能,解決了用戶資訊與交易間跨產品,多操作的紛繁之苦。在獲取資訊後即時把握市場機會,並透過演算法選擇手續費最低,滑點最低,路徑最短,交易最安全的方式完成交易。
從近幾個月的使用者體驗與回饋來看,基於「以意圖為中心」(intent-centric)而設計的QnA3 AI Agent 已經具備行動能力,能夠幫助使用者完成從資訊管理到資產管理的多項具體任務,使用者只需進行目標設定和等到結果即可。由此可見,ChatGPT 與QnA3 在文本理解和推理能力上都具有優異表現,能夠對用戶提出的問題做出詳細解答,但在垂直賽道中QnA3 透過RAG 而更顯優勢,同時,已經具備行為能力的QnA3 也能夠取代使用者實現AI+Trading 的「幫他做」。
3)權利管理AI+DePIN=“Decentralized Machine Learning”
如果要進一步提升Web3 的發展水平,現今市場存在兩個基本共識:
1)必須引進更多Web2 使用者將其轉換;
2)必須與實體經濟建立連結。
2023 年DePIN 的成長對Web3 生態系統產生了相當大的影響。隨著DePIN 邊界的擴大,它展示出成為面向消費者的應用層的資質,類似於DeFi、遊戲和社交,具有大規模採用的潛力,可以推動對底層鍊或生態系統消費者需求。
Pantera Capital 執行合夥人Paul Veradittkit 在其部落格中提到,DePIN 趨勢的成長也對去中心化治理產生了下游影響。目前大多數DAO,如Uniswap、Compound 和MakerDAO,幾乎都與數位或金融化資產有關。隨著DePIN 專案的成熟並逐漸將治理交接給DAO,DAO 協調購買、使用和維護實體設備(無論是伺服器、感測器還是硬碟)的需求將不斷增加。 DePIN 可能成為一個趨勢,將DAO 的治理權限從數位資產擴展到實體資產,最終可能需要DAO 運作和行為更像傳統公司,這可能是標誌著「Web3」在「現實世界」中被採用的轉折點[5]。
QnA3 產品一發布,就以問答的形式作為連結Web2 與Web3 兩個世界的橋樑。在引進數十萬Web2 用戶的同時,QnA3 也不斷探索更多將兩個世界連結的方式。
受到DePIN 熱潮的啟發,QnA3 於近期推出資料挖礦功能,將去中心化的實體設備的閒置算力用在AI 模型訓練中,使用Web3 世界的激勵機制為用戶提供被動收入,完成“用戶貢獻算力」、「算力產出資料訓練模型」、「更好的模型服務使用者」的閉環。 QnA3 選取的AI+DePIN 方式將去中心化硬體層與社區所有的新資料經濟融合在一起。
Messari 視角下的DePIN 基本上是鏈下數據生成結合鏈上數據確認兩大模組,核心是確權和規模效應,同時DePIN 有幾種模式,如定制專用硬件,比如Helium ;或者專用激勵層,將常用硬體轉換或加入為Web3 網絡,如Render Network,將個人閒置GPU 群組網賣給他人[6]。
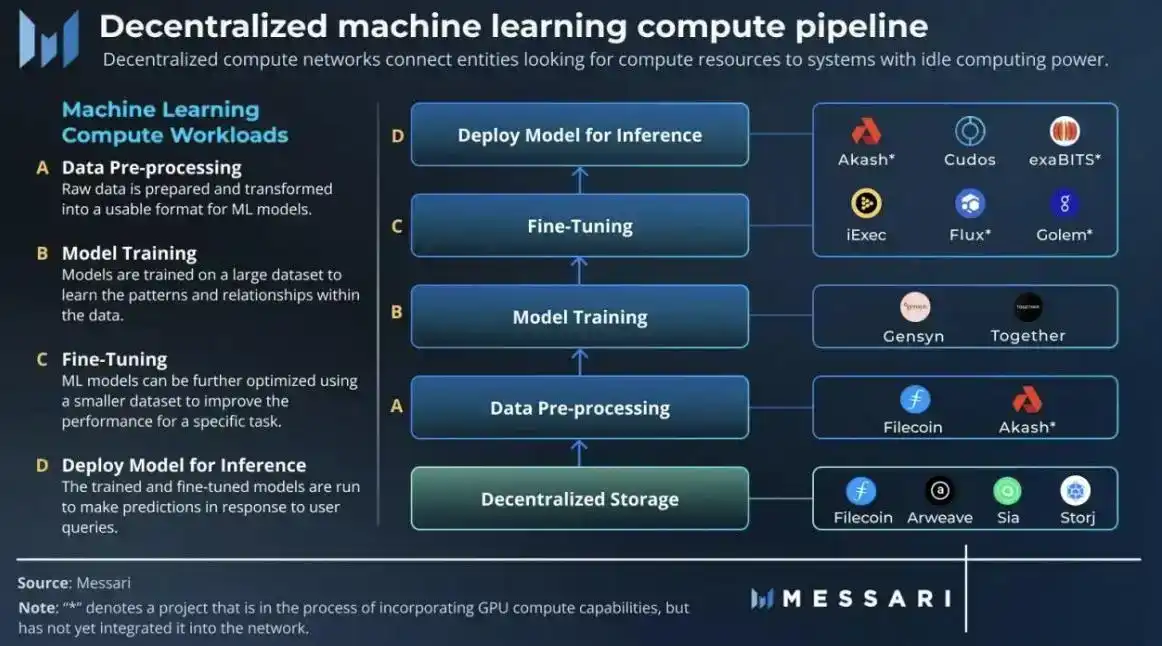
AI+DePIN 三個關鍵因素分別是:
1)擴展性能能力:DePIN 的硬體規格要求會影響算力提供者的數量和擴展速度;
2)採用便利性:減少摩擦是吸引更多算力提供者的關鍵;
3)代幣經濟學:為利害關係人設計和調整代幣經濟學。
QnA3 透過AI+DePIN 的模式,借助使用者的算力來幫助其完成資料抓取與資料清洗工作。同時,QnA3 認為在硬體物權的確權上,資料的價值必須被重視,人作為資料的主體需要新的數位權利,這才是DePIN 背後的價值取向,而非單純的資料上鍊和代幣激勵。與實際業務結合,QnA3 最終選取了Decentralized Machine Learning 的方向。 AI 專案的發展永遠將面臨計算瓶頸以及缺乏協作的限制。將AI 與DePIN 結合,QnA3 有望能夠逐步解決這些問題。
現在的嘗試只是QnA3 在Decentralized Machine Learning 應用場景下邁出的第一步,未來QnA3 還考慮推出硬體錢包和桌面機器人等更多拳頭產品,從而構建起以AI 為核心,涵蓋research,trading 與DeFIN的服務矩陣,形成AI Agent 為核心,涵蓋資訊管理,資產管理和權利管理的的產品框架,滿足使用者全生命週期的全場景需求。
QnA3 三大優勢
研究驅動
QnA3 是Crypto 計畫裡厚積AI 研究實力的產品,QnA3 與美國史丹佛大學、加州大學柏克萊分校、西北大學等知名科研機構合作,近期將會在頂尖期刊聯合發表學術論文。集齊OpenAI、Google DeepMind、Meta、Apple、Nvidia 等全明星陣容的技術顧問委員會。創始團隊主要base 在美國,來自騰訊、百度和國際知名投資銀行,在數據、AI 和crypto 領域經驗豐富。
使用者導向
憑藉對使用者的理解和對市場的敏銳,產品上線半年的時間裡,QnA3 已經實現了許多關鍵的版本迭代。特別是在更新頻繁的時期,幾乎每週都會推出新的功能,每兩個月就會推出重要功能。資訊管理功能已經可以滿足概念問題,即時問題,推理問題,分析問題,交易問題,價格問題等不同場景的需求;資產管理功能識別用戶意圖並幫助用戶完成;權利管理功能將在未來逐步實現用戶的物權和人權的數位化管理;真正實現以使用者為中心的產品實踐。
功能創新
產品功能迭代速度快,每週一個小版本。兩個月一個大版本。從時間發展的線路看,從立項到產品上線,不足三個月,然後上線半年時間收穫900w 用戶,覆蓋全球166 個國家和地區,每日UAW 接近200K,已經長居BNB 鏈榜首。
QnA3 的未來潛力
人機互動新方式
QnA3 快速成長的使用者數量驗證了對話式搜尋引擎的剛性需求。在Web3 垂直領域產品定位對標Google、ChatGPT 等巨頭具備資料和場景卡位優勢,更易於實現AI Agent 的場景閉環。

目前的人機互動方式主要以圖形介面和觸控互動為主,但未來QnA3 可以成為作業系統層級的入口,實現「對話即介面」的全新人機互動範式,或將帶來全新的軟體服務形態。
生產工具向生產力躍遷帶來商業化的龐大空間
AI 既是基礎設施,也是生產力引擎,如同蒸汽機,電力,電腦和互聯網。在AI 賦能下,眾多應用軟體將由生產工具向生產力躍遷,參與生產價值分配。而與QnA3 類似的工具軟體將逐步從輔助人類提效的「生產工具」成為獨立的增量「生產力」,從而或能夠直接參與生產價值的分配。在AI 應用未來能夠成為一部分「生產力」的情況下,未來的模式從收取效率提升「抽成(Take rate)」的角度來衡量其潛在能夠實現的增量價值上限。

QnA3 上線的Telegram 機器人可以幫助KOL 管理社群並在社群內實現問答、代幣分析和代幣交易,上線伊始便完成商業閉環。此外,QnA3 也與媒體、交易所和培訓網站達成合作。 QnA3 表示,這種生態樣本和抽成模式不同於交易所和交易機器人抽成的商業模式,他們在意的不是佣金,而是與用戶目標相同,成為利益共同體,從而參與增值收益的分配。
QnA3 的兩個夥伴:OpenAI & Google
相較於OpenAI
QnA3 vs ChatGPT 具備以下核心優勢:
1)專有數據和專有知識壁壘
許多高價值、特定領域產業依賴豐富的專有資料集。針對這些細分行業的人工智慧解決方案需要在這些數據上進行訓練。然而,擁有這些資料庫的實體將專注於保護其資料護城河,不太可能允許第三方無限制地存取這些資料庫以進行人工智慧訓練。因此,這些實體將在內部或透過特定的合作夥伴關係建立專門用於這些工作流程的專業人工智慧系統。這些系統將有別於一般的人工智慧模型。
2)資訊時效性強
ChatGPT 等大模型只包含訓練時的資料和語料,後續資訊無法及時更新。 QnA3 基於底層傳統搜尋引擎開發而得,具備時效性強的優點。
3)易於溯源
QnA3 產生的內容都在下方附有引用鏈接,在保證可靠性的同時便於用戶溯源或深入研究。
4)減輕幻覺
通用大模型的幻覺問題在細分行業高品質的追求下是不可接受的。 QnA3 有專屬的資料篩來源和篩選機制,透過多道流程來規避這個問題。
AI+Research 與大模型技術對比
生成式AI 語言理解與生成能力突出,但存在幻覺、數據缺乏即時性等劣勢。生成式AI(Generative AI)是一種基於AI 技術的機器學習模型,它對海量訓練資料進行學習並根據其特徵生成與原始資料相似的全新內容,生成內容可以為圖像、視訊、音樂、語音和文本等。近年來電腦硬體效能的提升和預訓練技術的發展使生成式AI 能力實現躍遷,以ChatGPT 為代表的大型語言模型具備語言理解能力強大、多樣化生成能力等優點,被廣泛應用於各行各業。但生成式AI 無法做到即時更新,且受限於訓練數據,可能無法涵蓋相對小眾、缺乏通用性的長尾知識。同時,生成式AI 對生成內容的可控性較差,有「幻覺」問題,使用者也難以直接驗證答案。
檢索增強生成(RAG)融合外在知識與模型先驗知識,有效彌補生成式AI 缺陷。檢索增強生成(Retrieval Augmentation Generation)由檢索和生成兩部分組成,首先在知識庫中根據需求召回最匹配的文檔內容,然後作為提示詞輸入模型生成答案。
5)專業作為品質的核心
細分行業的工作流程要求高品質,獎勵任何品質改進動作。任何應用於細分行業的人工智慧解決方案都需要不斷調整以提高品質。反應速度和反饋效率對於品質至關重要。通用模型本身的高相容性在這裡會導致品質的差距,可以想像如果火箭的人工智慧模型被GPT-4 這類的通用模型代替,結果將是毀滅級的。這種品質差距必然導向專業化調整。
相較於Google
QnA3 vs Google 等傳統搜尋引擎具備以下核心優勢:
1)頁面清爽,答案直接
輸入一個問題時,傳統搜尋引擎呈現多個並列鏈接,其中穿插大量廣告,而QnA3 會結合最相關的鏈接直接生成精煉答案。提高資訊獲取效率,減少關鍵字查詢、篩選、連結點擊和頁面瀏覽;讓Web3 用戶在嘈雜的市場環境和海量資訊中直接了解事情的真相,並透過簡潔明了的個人化答案做出決定。
2)細分領域精細搜索
QnA3 作為Web3 知識庫和AI+Research 工具,使用者在Web3 垂類領域精確搜索,結果更具針對性。
3)問題拆解與追問能力
基於大模型的理解能力,QnA3 可以對用戶提問逐步拆解並追問澄清,精確把控用戶需求。在谷歌中搜尋是什麼、為什麼類型的問題,谷歌能都應對自如。但涉及更複雜的問題,如「某個代幣現發展階段價值不值得購買」、「請對於XX 代幣進行技術面分析」,「比較BTC 與ETH 的優劣」,QnA3 顯然比Google會回答得更好,QnA3 的引擎有著更強大的理解問題、總結問題、拓展問題的能力,無疑讓它有了更強的競爭力。
4)回饋功能
QnA3 產生回答後,使用者可以對其準確性進行回饋,以強化學習的回饋機制幫助其進一步提升模型準確性。 QnA3 以積分的方式和使用者進行鏈上互動。
在Web3 領域,能做,做得好,有很大的差別。 Google 在其第一款搜尋產品後,幾十年間發展出了涵蓋Android,Gmail 和Map 的超大產品矩陣。 OpenAI 在去年的開發者大會上也宣布推出GPT Sotre。現在Google市值1.7 兆美元,OpenAI 估值接近千億美金。目前,QnA3 透過其核心產品在廣大Web3 用戶中證明了自己,從長遠發展上來看,QnA3 未來一定會在Cyrpto+AI 這一領域添上更加濃墨重彩的一筆。
[1]《火炬,鑰匙,橋樑與未來》https://reurl.cc/eL3Kvm
[2] Lewis, Patrick, et al.「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.」ArXiv abs/2005.11401 (2020): n. pag.
[3]《LLM Powered Autonomous Agents》https://lilianweng.github.io/posts/2023-06-23-agent/ + CICC Research Department
[4]《意圖之上,行為之下》https://reurl.cc/dL23dk
[5]《DePIN:Decentralized Hardware Meets the New Data Economy》https://www.veradiverdict.com/p/depin?utm_source=profile&utm_medium=reader2
[6] Messari,《crypto-theses-for-2024》https://resources.messari.io/pdf/crypto-theses-for-2024.pdf












