

前言:
萬向區塊鏈董事長兼總經理肖風博士曾說過,不管是元宇宙、區塊鏈還是Web3.0,本質其實都是講同一件事,就是人類社會在數字時代裡的去中心化趨勢。因此,無論在元宇宙裡,還是Web3.0時代,個人數據成了個人資產,而個人數據隱私問題也成了“新世界”裡的核心問題。
本篇將從“用戶畫像”的角度來探討數據隱私問題,希望能對各位思考元宇宙或Web3.0的隱私安全保護,提供一個思路。
本文作者:萬向區塊鏈首席經濟學家辦公室王普玉
本文審核:萬向區塊鏈首席經濟學家鄒傳偉
什麼是用戶畫像?
用戶畫像最早由交互設計之父Alan Cooper提出,圍繞四個要素:人物、時間、地點和事件將用戶的信息標籤化(如圖1所示),再根據標籤有針對性地收集用戶社會屬性、消費習慣、偏好特徵等各個維度數據,並對這些特徵進行分析、統計,挖掘潛在價值信息,從而抽像出用戶的信息全貌。
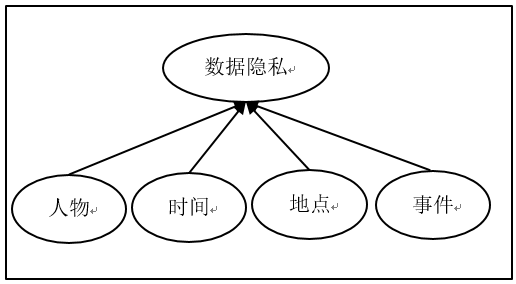
圖1:個人信息四要素
用戶畫像是一把雙刃劍,方便了用戶的生活,但同時又侵犯了用戶的個人隱私。例如,當用戶使用支付寶掃描二維碼完成一筆交易支付,大數據分析工具會捕捉用戶的消費金額、地點、時間等行為數據,而隨著數據標籤的積累和數據量的增加,實現個人信息四要素的關聯,形成一副完整的用戶畫像,平台能夠對用戶行為進行分析,並實現精準營銷。
用戶畫像標籤是怎麼設計的?
1
標籤框架
市場目前有四種標籤框架,分別是:
(1)基於營銷觸點的用戶標籤體系;識別用戶的付費流程和付費意願階段,為營銷提供明確的時機,例如阿里系的標籤框架AIPL,將用戶對品牌的認知階段分為感知、有興趣、購買和忠誠四個階段,再根據四個階段的營銷動作制定細分標籤。
(2)基於增長漏斗的AARRR模型;此模型又稱海盜模型,由美國著名風險投資機構創始人戴夫.麥克盧爾提出,由Acquisition、Activation、Retention、Revenue、Refer(拉新、促活、留存、創收和分享)五個單詞首字母拼寫組成,識別用戶所處的增長狀態,對不同生命週期的用戶執行不同的增長策略。廣告主利用該模型,可以有針對性地對每個模塊客戶實施區別化的營銷策略,提升轉化率。
(3)基於用戶價值的分層模型;比如RFM模型、ARGO模型,還有用戶忠誠度和用戶生命週期模型等。其中RFM模型被廣泛應用於傳統銷售行業。 RFM分別代表Recency最近一次消費、Frequency消費頻次和Monetary消費金額。將每個維度劃分為高、中、低三種情況,利用重要(價值、發展、保持、挽留)和一般(價值、發展、保持、挽留)要素8個要素構建出四個像限,直觀的將用戶劃分為8個不同層次,識別用戶的價值做用戶分層,對不同價值分層的用戶執行不同的運營策略。
(4)基於用戶偏好的模型;基於用戶對產品的功能或商品偏好做區分,提供營銷人員信息去進行個性化服務,如房產領域的購房目的、區域位置、價格等。
2
標籤的設計與應用
以典型的電商業務為例介紹標籤的設計流程,總共三步,包括業務流程梳理,標籤設計的商業目標確定,以及標籤的設計。
(1)業務流程
業務流程漏斗包括啟動APP、註冊登錄、瀏覽活躍、深度行為、付費和重複付費、到最後的沉默流失。如圖2所示,根據業務流程梳理出每一步的考察維度。再根據用戶在這方面的行為,去構建用戶偏好的標籤。
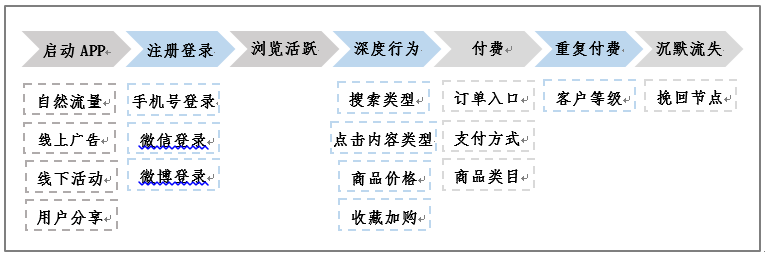
圖2:根據業務流程的用戶畫像
(2)商業目標
基於不同的商業目的,企業會嘗試從不同維度構建標籤,其目的大多一致,即通過精細化運營整體的交易金額。根據不同的商業目的,企業會對業務流程進行拆解。如交易金額可以拆分為新用戶的交易額和老用戶的交易額;達成交易的過程又可拆分為新增啟動、註冊、瀏覽詳情、深度行為、最後到付費。對拆解出來的每一環節使用不同策略去提高交易金額,如圖3所示。
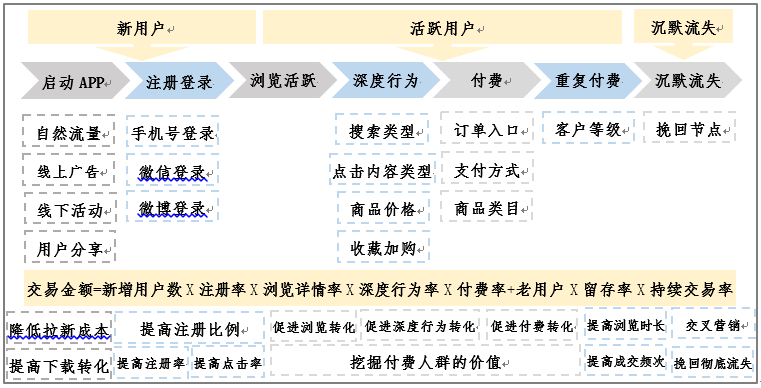
圖3:用戶畫像商業目標實現方法
(3)標籤設計
用數據計算邏輯來看,只有當輸入值滿足限制條件,最終結果才能落到一個期望的範圍內。因此,商業交易中,期望結果如圖3中位於底層的不同目標,而標籤則是這些不同的輸入值,企業試圖用大數據分析得到這些輸入值的合理範圍,以得到期望結果,於是就出現瞭如圖4所示的模型。
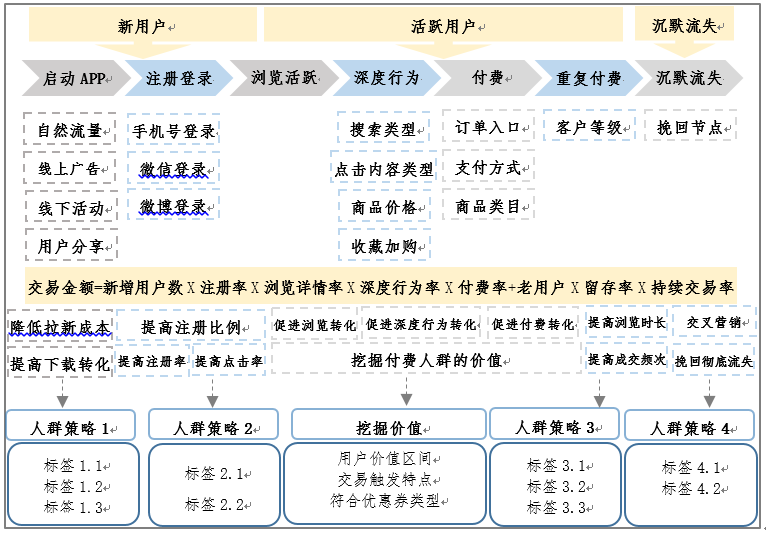
圖4:基於商業價值的用戶畫像標籤設計
標籤類型根據打標籤的方式又分為3種,分別是統計類標籤、規則類標籤和機器學習算法類標籤。
例如小張在社交APP資料顯示男性,和網友見面時對自己的描述是“濃眉大眼臉型方正,穿著很有設計感的裙子”;小張在結賬時使用刷臉支付,沒有獲得當天的女性九折優惠。因此,如何判斷小張的性別?
① 統計標籤
小張在社交APP填寫的為男性,所以我們認為他是男性,這類基於確切資料確定的標籤,叫做統計標籤;對於用戶而言,其性別、年齡、城市、星座、近7日活躍時長、近7日活躍天數、近7日活躍次數等字段可以從用戶註冊數據、用戶訪問、消費數據中統計得出。而該類標籤構成了用戶畫像的基礎。
② 規則標籤
小張穿的是一件很有設計感的裙子,按照人們的慣性思維,張三為女性。這個判斷是基於人們設定的規則,只要有人穿裙子就是女性,這類標籤叫做規則標籤,即基於用戶行為確定的規則。在實際開發畫像的過程中,由於運營人員對業務更為熟悉,而數據人員對數據的結構、分佈、特徵更為熟悉,因此歸類標籤的規則由運營人員和數據人員共同協商確定。根據不同標籤所獲取用戶數據的準確性,標籤的規則會不定時進行調整。
③ 機器學習算法標籤
攝像頭結合基於多種特徵的算法對小張是女性的概率進行判斷,由於小張長相很陽剛,算法判定其為男性,因此,小張刷臉支付沒有獲得活動女性優惠。該類標籤通過機器學習挖掘產生,用於對用戶的某些屬性或某些行為進行預測判斷。
對於目標人群有明確的行為數據,企業會根據用戶偏好標籤收集數據;但如果目標人群的行為數據較少,比如新用戶和沈默用戶,一般從他們所處的生命週期標籤出發,去極化促進轉化和召回的策略。
數據來源
1
數據獲取途徑
用戶畫像是一個複雜的過程,包括數據採集、數據處理、數據分類及數據存儲等,如圖5所示,展示了用戶畫像的具體架構,我們將對其最底層的用戶數據採集途徑進行詳細分析。
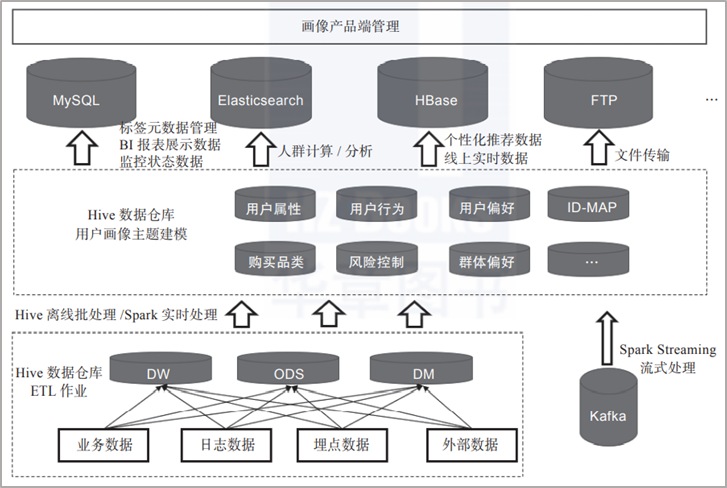
圖5:用戶畫像數據倉庫架構
從圖5中可以看到,用戶畫像底層數據的主要獲取途徑包括兩大部分:內部系統數據及外部數據,而內部系統數據又包括業務數據、日誌數據和埋點數據。
(1)內部數據
① 業務數據
包括用戶信息表、商品訂單表、商品評論表、搜索日誌表、用戶收藏表、購物車信息表。
用戶信息表包括了用戶編碼、用戶姓名、用戶狀態(未註冊、已註冊、已註銷)、郵箱編碼、用戶生日、性別(自然性別、購物性別)、電話號碼、是否有圖像、創建時間、註冊日期、歸屬省、歸屬市、詳細地址等等;
商品訂單表包括訂單來源標識(App, Web,H5,其他等)、用戶編碼、用戶姓名、訂單號、商品編碼、商品名稱、訂單生成時間、訂單日期、訂單備註、訂單狀態(待支付、已完成、已取消、已退款、支付失敗等)、訂單狀態時間、訂單金額、付款賬戶、付款方式等等;
商品評論表存放用戶對商品的評論信息,主要字段包括用戶id、用戶姓名、評論內容、評論圖片、評論狀態(待審核、已審核、已屏蔽)、訂單id、創建時間、創建日期、評論用戶IP、更新時間等;
用戶收藏表記錄用戶在平台上收藏商品的數據,字段主要包括用戶id、收藏日期、收藏時間、商品id、商品名稱、收藏狀態(收藏、取消收藏)、修改日期、修改時間等。
購物車信息表記錄用戶將商品加入購物車的數據,主要字段包括:用戶id,商品id,商品名稱、商品數量、創建日期、創建時間、圖書狀態、修改日期、修改時間等。
② 日誌數據
訪問日誌表存放用戶訪問App的相關信息及用戶定位數據的服務(LBS),通過在客戶端埋點,從日誌數據中解析出來。主要字段包括設備登錄名、用戶id、設備id、訪問時間、上報時間(終端記錄用戶點擊按鈕時間)、用戶所在省份、用戶所在城市、上一個頁面url、當前頁面url、操作系統、登錄日期、經度、緯度等。
搜索日誌表存放用戶在APP端搜索相關的日誌數據,主要字段包括設備登錄名、用戶id、設備id、搜索id、搜索日期、搜索時間、用戶搜索的關鍵詞、標籤內容、每個訪問的隨機數等。
③ 埋點數據
埋點日誌表是存放用戶訪問App或網頁,用鼠標或觸屏點擊頁面時留下的打點記錄。通過客戶端做埋點,做用戶頁面統計及統計操作行為監控,主要字段同日誌數據。
埋點是企業為了盡可能完整的收集可以體現用戶使用場景和真實需求的行為數據,也是圍繞著圖1中的四要素,但數據框架通常是4W(whowhenwherewhat)+1H(how),分別對應著四要素中的人物(who)、時間(time)、地點(where)、事件(what + how)。
who
用來分析誰完成了這個行為,使用唯一的用戶ID將行為與用戶關聯起來。常用的數據包括用戶id、手機號、身份證、設備或應用識別碼。
where
定位用戶在什麼地方完成該行為,常用的數據包括IP(web、手機)、GPS(手機)、自主填寫位置(大眾點評、餓了嗎、美團外賣等)。
when
定位用戶什麼時間完成該行為,常用數據是時間戳和當地時間。
what
定位用戶當前行為,為了能夠更精細化管理,記錄的信息越來越詳細,具體指標包括內部系統數據中的業務數據,通過埋點的方式來獲取。
how
獲取用戶發生髮生行為時周邊環境、手段、設備等,盡可能在數字世界裡還原用戶所處環境,常用數據包括操作系統、設備版本、設備型號、網絡環境(WIFI、5G)、設備版本(用戶使用設備的版本號)、瀏覽器、上級頁面等。
當用戶產生某個行為,觸發埋點後,將4W+1H相關數據傳輸到後台進行分析,以每天、每小時或者一定數據限值的固定方式上報。有些企業只會收集與自身業務有關的用戶畫像標籤數據,而大多企業會過度收集信息,即大量與自身業務無關數據。例如用戶在圖片管理軟件上傳了一張圖片,軟件會收集到設備信息、用戶信息,圖片如果是自拍,用戶畫像的具體外貌也將被綁定,而照片中建築、門牌號、店鋪名都有可能暴露用戶的身份和位置,這些信息均有助於企業了解用戶的財務狀況、生活習慣等等信息。
(2)外部數據
外部數據包括多項數據,主要用於彌補內部用戶標籤不足或數據量不足問題,通過結合外部數據獲取一個更加全面的用戶畫像。主要外部渠道包括:互聯網公開數據、付費數據(數據提供商)、網絡採集數據、通過人脈獲取數據、百度指數和站長工具等檢測數據。下面介紹幾個主要渠道:
① 互聯網公開數據
公開數據主要是圍繞全球、國家、地方及企業宏觀層面的統計數據,不會對用戶畫像有直接作用,但能夠提供參考。例如,中國國家統計局(http://data.stats.gov.cn/index.htm),包括了我國經濟民生等多個方面的數據;CEIC(www.ceicdata.com/zh-hans),擁有超過128個國家的經濟數據,能夠精確查找GDP、CPI、進口、出口、外資直接投資、零售、銷售、以及國際利率等深度數據;還有包括Wind、搜數網、中國統計信息網、亞馬遜公開數據集、figshare、github等等。
② 付費數據
大數據交易中心
2015年各地開始興建大數據交易中心,截至2019年底,已有30家大型數據交易所(中心),我國大數據的交易模式可大致劃分為四種,政府牽頭或背書的交易所(中心)、行業機構為主的行業數據交易模式、大型互聯網公司及IT廠商主導的數據交易平台、垂直數據服務商主導的市場化數據交易模式。
企業間數據共享
類似信貸企業很難通過自有數據完成用戶畫像,通常會與行業合作夥伴共享數據。
其他
網絡攻擊者通過各種漏洞,佈點SDK,獲取所需數據,並在地下交易市場進行出售,形成了包括黑客、多級料商(數據中間商)、買家一條完整的黑色產業鏈,通常分為四級:第一級是黑客或公司內部員工盜取用戶個人數據;第二級盜取的用戶信息售賣至料商;第三級是料商不斷發展代理商,將數據進行倒賣;第四級是信息使用者,獲取數據後,進行用戶畫像補充、電話營銷或實施電信詐騙。如某料商在向記者採訪時表示:“個人普通信息比如電話、微信、QQ號等,平均拿貨成本每條信息0.4元,單條銷售價格0.7-0.8元,每個月流水達到40-50萬元,金融、教育、醫美等行業都做,市場需求量很大。”
2
數據採集技術
互聯網時代,為了追踪、分析與說服消費者,廣告商已經開發了很多便捷與成熟的營銷跟踪技術,在線廣告營銷伴隨著每一個上網瀏覽網頁的用戶。廣告行業借助不同的技術,如Cookies、Flash cookies、Beacons、瀏覽器指紋,對用戶行為進行追踪。
① Cookies
Cookies是網站服務器在用戶的內容或硬盤中保存的用來記錄用戶瀏覽的網頁地址、網頁停留時間、網頁上鍵入的用戶名、密碼、用戶瀏覽習慣等方面的小型瀏覽文件。它並非由本機生成,通常在用戶瀏覽網頁時,從所瀏覽的網站發送過來,用來檢測用戶在做什麼的小型數據包;它不僅可以對用戶行為進行追踪,還可以為用戶推薦曾經訪問的網址,省去用戶重新輸入網址的麻煩,用戶不必重新輸入用戶名和密碼,就能實現登錄。此項技術引發的最大問題是在用戶完全不知情的背景下,對用戶行為進行跟踪、記錄,這往往會引發第三方(如行為廣告商)的接入。廣告商在採集到Cookies數據後,會有針對性地通過行為營銷的方式向用戶投放其可能感興趣的廣告。目前主要的應對方法是使用瀏覽器的無痕模式,或定期對瀏覽器Cookies清理,減少數據洩露。
② Flash cookies
隨著技術的發展,開發人員發現了更好的方法——Flash cookies。傳統Http下的cookies不穩定,用戶可能會隨著清除掉瀏覽器中的Http Cookies,或者在瀏覽器選項中,手動將它設置為禁用模式而避免數據被採集。 Flash cookies則可以對用戶刪除的Http cookies進行重寫,獲得重生,這樣原來保存的數據在刪除後又重新呈現在分析者面前。而傳統禁用或清除瀏覽器中Cookie的方法,無法抗衡網站對用戶網上瀏覽歷史的重寫、跟踪和記錄。
③ Web Beacons
網絡信標(Web Beacons),又稱網頁臭蟲(Web bug),是可以暗藏在任何網頁元素或郵件內的1像素大小的透明GIF或PNG圖片,常用來收集目標電腦用戶的上網習慣等數據,並將這些數據寫入Cookies。不同於Cookies可以被瀏覽器用戶接受或禁用,Web Beacons只以圖形交換格式(GIF)或其他文件對象的形式出現,只能通過檢測功能發現,最初的涉及有積極意義,如跟踪侵犯版權的網站。
信標API(Beacon API)則是Web Beacons的升級版本,它不需要使用不可見圖像或類似手段就可以達到相同目的,旨在方便Web開發人員能在用戶離開頁面時將信息(如分析或系統診斷數據)發回Web服務器。使用Web信標API能夠不干擾或影響網站導航來完成此種追踪,並且對最終用戶不可見。這項技術在2014年後相繼引入Mozilla Firefox和Google Chrome網頁瀏覽器,但2021年谷歌又宣佈為保護用戶隱私,已經放棄使用追踪個人網站瀏覽記錄。
④ 瀏覽器指紋
不同用戶的瀏覽器都有自己的特徵,網站可以檢測用戶的瀏覽器版本、操作系統類型、安裝的瀏覽器插件、屏幕分辨率、所在時區、下載的字體及其他信息,這種通過瀏覽器對網站可見的配置和設置信息來追踪Web瀏覽器的方法,稱為“瀏覽器指紋”,它如同人手上的指紋一樣,具有個體辨識度。如果要避免指紋追踪,用戶需要禁用網站的JavaScript與Adobe's Flash技術。即使電腦高手,面對指紋跟踪技術,也很難保護自己的隱私。最初瀏覽器指紋是狀態化的,需要用戶登錄賬戶才能得到有效信息;升級後的瀏覽器指紋通過不斷增加瀏覽器的特徵值從而讓用戶更有區分度;到現在已經基於人的行為、習慣為用戶建立特徵值甚至模型,在不同設備上,沒有使用用戶登錄的情況下,僅通過瀏覽網頁的習慣等就可以鎖定到具體的用戶身份,這項技術正在研究中。目前來看指紋跟踪很難被阻擋,只要用戶使用瀏覽器上網,用戶的網上行踪就如同公開狀態一般。
⑤ SDK
在檢測網站或軟件上用戶行為時,通常在網站或軟件上增加一些代碼,當用戶觸發相應的行為,進行數據上報,也就是代碼埋點。這樣的代碼,在網站上稱為檢測代碼,在app上成為SDK(Software Development Kit)。市場上目前有一些相關工具,如GrowingIO、GA、神策等。
用戶畫像數據問題及分析
從營銷學角度來看,用戶畫像技術幫助市場供方精准定位客戶,同時為客戶提供個性化服務,有效提升了市場交易效率。雖然用戶畫像技術有其社會價值,但在前面兩大部分,我們對用戶畫像的標籤框架、設計與應用、標籤數據來源及數據採集的相關技術進行的詳細梳理,發現企業在用戶畫像過程中存在較多數據安全問題,包括數據交易渠道合規性問題、非法數據採集技術、過度收集用戶數據、用戶個人數據隱私缺乏保障機制等。
1
外部數據獲取渠道合規性問題
正常情況下,用戶提供個人數據和平台提供個性化服務形成了一個商業閉環。但從前面分析中,為了用戶畫像,企業自有數據無法滿足標籤數據量需求,企業通常需要從外部獲取一些數據。在數據交易中,滋生出一些自發組織的灰色市場,如圖6所示,平台或其代理將用戶個人數據明碼標價的形式銷售給第三方機構,出現了以用戶、平台或其代理和第三方機構為代表的商業閉環,第三方機構通過對用戶信息的分析,提供一些“個性化服務”給用戶,而這些頻繁的個性化服務廣告對用戶生活帶來一定的影響。由於數據缺乏管理,部分數據會流入到一些非法組織手中,向用戶進行虛假產品營銷及詐騙。
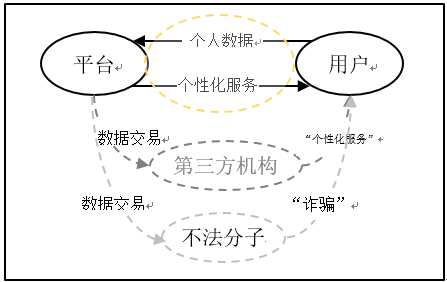
圖6:企業數據交易閉環圖
目前,市場上合規的數據交易渠道較少,2015年各地興建大數據交易中心,旨在促進數據合法交易及流通,服務市場經濟。但近幾年數據表明並未達到市場預期,且與初期設想有較大差距,主要問題在於數據確權、數據定價、數據交易等數據要素市場化、流通機制設計等方面存在很多空白,容易觸及法律紅線。根據《網絡安全法》第四十二條規定:“網絡運營者不得洩露、篡改、毀損其收集的個人信息,不得向他人提供個人信息。但是,經過處理無法識別特定個人且不能複原的除外。 ”而我們從前面分析內容可以發現,用戶畫像的前提是要識別個人身份,否則無法從技術上實現對個人的用戶畫像。除了《網絡安全法》中提及要實現個人數據的匿名化,在數據交易和共享環節還需要獲取用戶授權同意,這將極大增加了企業數據合規成本。
因此,促進外部數據獲取渠道合規性需要解決以下問題:
個人數據匿名化(非去標識化),實現關聯要素“人物”的切斷。在個人信息匿名化的情況下,完成用戶畫像(可用不可見);例如使用聯邦學習、多方安全計算、差分隱私等方法。清晰的數據確權方案;企業低成本數據使用授權方法;建立健全的數據定價和利益分配機制。
2
防止非法數據採集方式以及數據過度採集
早期用戶數據分析是圍繞業務數據,即通過過往的消費記錄形成客戶的消費畫像。業務數據基本能夠分析出客戶對於品牌、顏色、款式的喜好以及價格承受能力等,但這些數據不足以進一步挖掘客戶的消費潛力。平台側通常需要更多的行為數據,抓住客戶具有時效性的衝動需求,為此平台方通過我們前面提到的Cookie、Flash Cookies、Beacons、瀏覽器指紋、SDK等技術,在客戶不知不覺中,收集行為數據並分析數據,用於用戶畫像及精準營銷。行為數據的收集如圖7所示:
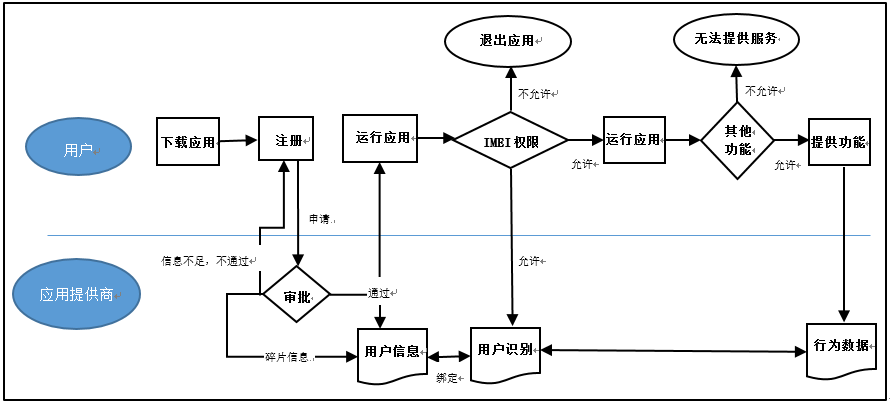
圖7:應用提供商數據獲取方式
在註冊環節,應用提供商獲取用戶的基礎數據,再通過設備唯一的IMEI(國際移動設備標識碼)授權(局域網是通過Mac Address來確認設備地址),可實現用戶與基礎數據的綁定,即幫助應用提供商來判斷發生的數據具體來自哪個用戶。之後通過獲取更多權限,例如攝像頭、照片、通訊錄、定位、應用列表等等功能,讀取用戶的實時行為數據,而這些行為數據被應用提供商採集,進行詞云分析,分析用戶的性格、愛好、各種生活喜好等,對用戶進行畫像。隨著數據的積累,在數字世界形成了一個與物理世界相映射的數字人物。這個數字人物的控制,在將來有一天通過仿真技術,數據持有人能夠做到對數字人物的下一步行為的預測,同步引導物理世界的用戶完成他們想要的目的,這將對所有用戶是危險的一件事情。
近年來,一些手機終端公司陸續提供了一項設備數據保護的新技術——OAID(匿名設備標識符),使用虛擬的ID身份替代設備原有的IMEI成為設備識別標識。 OAID通過提供隨機匿名身份,用於各種應用的設備綁定,讓設備能夠正常運行且讓應用提供商無法識別具體的用戶身份。但這種模式下,仍然有以下問題:
① 未從根本解決數據安全問題
OAID雖然有效解決用戶數據無授權採集問題,即讓應用提供商無法通過真實終端設備識別碼映射到具體的用戶行為,但該方法無法徹底解決數據安全問題,因為應用提供商依然可以通過應用註冊賬戶留下的個人信息識別具體的用戶。關於註冊信息安全問題,目前的解決方法較為複雜,通常使用虛擬手機號或臨時郵箱註冊賬戶,並需要做到頻繁註冊新賬戶來迷惑應用提供商。
② 無法避免終端提供商收集數據
OAID虛擬身份來自中心化機構,雖然通過該方法避免應用提供商使用各種技術收集終端數據,但終端提供商能夠通過OAID映射到IMEI,控制權相當於從應用提供商轉交到終端設備提供商手裡,仍然有數據洩露風險。
關於數據過度採集問題,用戶普遍表現出排斥的態度,終端服務商也通過OAID等技術防止各種應用對用戶信息採集。但隨著互聯網技術的進一步發展,我們將迎來一個與物理世界相映射的數字世界,無法避免更多數據會從物理世界映射到數字世界。既然大勢所趨,我們需要做的不是防止數據被採集,而應該將更多注意力放在如何保護採集到的數據安全,即用戶的每條數據被採集,只能用於同一場景下服務於本人,也就是圖5中形成平台與用戶的閉環,避免數據流向第三方機構、非法組織等。
3
用戶個人隱私保護
用戶畫像雖然提升了交易效率以及降低了供應成本,但用戶的隱私同時也被其他機構或組織掌握,存在多種洩露風險,包括:第一、企業通過第三方出售用戶數據;第二、企業員工盜取數據,並通過非法途徑售賣;第三、網絡攻擊者通過技術漏洞或盜取企業員工身份獲取系統中的用戶數據。目前各公司主要從道德層面承諾對數據的保護,但一位知名公眾人曾在公開場合表示:中國人願意犧牲隱私,換取便利。而央視對此的評論是:人們最害怕的不是他說了錯話,而是科技巨頭對用戶核心利益的熟視無睹,成為一種脫口而出的真心話。
在數字化時代,數據就是原油,它不僅能推動經濟發展,還是實現信息技術突破的重要燃料,如果一味強調保護數據,肯定會逐漸喪失已逐漸滲透進我們每個人生活、每個角落的便利和無限商機,不能因為要倒掉洗澡水,就把孩子也潑出去。隱私保護和經濟發展並不是二元對立,目前的解決方案包括區塊鏈技術、數據匿名化處理、差分隱私、多方安全計算、矩陣變換等數據脫敏技術,都能做到用戶數據隱私,但這些技術的建設不僅需要平台端買單,還會影響到平台的現有核心利益,因此當前市場對該類技術推行非常緩慢。這一局面逐漸出現轉機,比如近期滴滴打車、運滿滿等互聯網平台因為數據採集不合規問題被叫停的事件,對市場起到了很好的警示作用。
End










