

前言:如果說,ChatGPT的出現,象徵著一場新的、關於“智能”的工業革命的萌芽正破土而出。那麼,預言機的落地,代表著一次新的,關於“數據”的區塊鏈變革的哥倫布之旅。
“你是誰?”
“我是一個由OpenAI訓練的大型語言模型。我旨在幫助人們解答問題和提供信息。由於我是一個計算機程序,所以不會感知或者思考,只能通過已有的數據來回答問題。如果您有任何問題,請隨時告訴我。”
ChatGPT:挖掘數據價值
ChatGPT,無疑是近期互聯網上最火的一個話題。據《財富》報導,ChatGPT在發布僅僅五天后就完成了Facebook耗時10個月才完成的目標——用戶超過100萬。 2月1日,ChatGPT月活用戶破1億人,ins實現這一數據用時兩年,TikTok用時9個月,而ChatGPT僅用60天。
火爆程度,可見一斑。
作為這個時代技術的傑出結晶,ChatGPT帶來的是不可預知的革命。無論你喜歡不喜歡,以ChatGPT為代表的AIGC(生成式人工智能)將改變世界。
比爾蓋茨也意味深長地說:ChatGPT出現的重大歷史意義,不亞於PC和互聯網誕生。

伴隨著ChatGPT的誕生,其愈發強大的AIGC(生成式人工智能)能力使得不少職業人陷入“職場危機”。甚至有人會擔心AI會不會取代人類。其實,AI代替人類工作的言論,並不是第一次出現,幾年前便初見端倪。
2017年12月麥肯錫全球研究院(McKinsey Global Institute)發布的《失業與就業:自動化時代的勞動力轉型》報告稱,到2030年,保守估計全球15%的人將因AI技術發展而發生工作變動,激進預估則影響30%的全球人口,中國屆時預計有幾千萬至上億人需重新就業。
當人們仍對報告中的預測不以為意時,2022年9月,科羅拉多州博覽會藝術比賽的數字類別中,AI畫作《太空歌劇院》一舉奪魁,再次引發“AI能否取代人類”的巨大爭論。如今,ChatGPT的橫空出世,引發全球規模的對AI“威脅”就業所產生的職業生存焦慮的討論。
毫無疑問,ChatGPT是當前人工智能領域重大突破的傑作,同時,不可否認的是,ChatGPT依然存在很多問題。儘管ChatGPT一個基於統計規律的大語言模型,它有人類無懈可擊的語言天賦,但是只能做聯想而不能完成“邏輯推理”。從這個角度來講,ChatGPT會傾向於製造出令人信服的回應,當然其中可能包含“生成的”幾個事實錯誤、虛假陳述和錯誤數據,因為作為一個自然語言處理模型,它也不知道高達數十PB的無監督訓練數據裡什麼是“事實”,這更像一個有點滑頭的“虛擬助手”。
另外,因為在訓練過程中,為了識別人類指令而注入過大量“指令”知識,ChatGPT會對“指令”本身非常敏感,但同時會對一些上下文無關,需要“事實依據”做判斷的歧義詞識別不高。也許,對大多數普通人來說,ChatGPT都是一個合格的助手,因為所有關於人類語言的技能它都很精通(或者在可見的未來里會很精通),比如歸納總結、翻譯、書寫文章、風格修正、翻譯、潤色、寫代碼等等。因而,從事這些工作的勞動者,如果不能掌握將ChatGPT作為助手的技能,也許將會成為最早期被機器取代的人。
概而言之,ChatGPT是超級工具,不是超級智能,它不會替代人類,而是在升級行業。它將極大降低創意和執行門檻,與人類相輔相成。
全球最大廣告集團WPP首席執行官說:搶走你工作的從不是AI,而是其他掌握AI工具的人。
AI發展那麼多年,那為什麼ChatGPT能夠成為AI賽道的黑馬?

歸根結底,源於對數據的“利用”。
當前,人工智能重大研究方向就是NLP任務(自然語言處理),也就是機器要讀懂人類語言。而NLP任務(自然語言處理)有兩大方向,一個方向是谷歌的雙向(BERT)技術,另一個方向就是OpenAI的自回歸(GPT)技術。
早在2018年6月,OpenAI公司提出初代GPT模型。同年10月,谷歌公司公佈了自己的BERT模型,大幅度刷新了自然語言處理領域幾乎所有最優記錄,從此開啟了預訓練大模型時代。
在此後的4年時間裡,預訓練語言模型如BERT 和GPT(GPT-1和GPT-2,這些ChatGPT的前身),已成為當前自然語言處理領域的主流技術趨勢。這些模型參數從3億到1.75萬億不等,也因此被稱作大語言模型(Large Language Model)。
而這些預訓練大模型的本質是在使用更大的模型、更多的數據去找到對人類更好的、更通用的“語言模型”。也正是因此,包括BERT和GPT在內的大語言模型,在預訓練過程中其實就已經獲得了相當數量的詞彙、句法和語義知識,僅僅只需要少量標記數據對模型細化,就可以完成各種各樣的自然語言處理任務。

通過挖掘“數據”的價值,去賦予場景生態,這種類似的橋段是不是和“預言機”十分相似呢?只不過,ChatGPT仍屬於Web2.0時代的產物,仍然具有一定的局限性。
如果說,ChatGPT、AIGC則完全無視你的主權,無所顧忌地抓取全球數據進行訓練,最後製造出一個屬於自己的“超級大腦”。那麼,區塊鏈技術的原教旨價值是“去中心化”,希望打破這種壟斷,並重構一種新的分佈式網絡,讓普通人重新擁有自己的數據主權。
預言機:鏈接數據橋樑
提及到區塊鏈,想必大多數人想的是比特幣、以太坊,再不濟就是炒幣、挖礦、DeFi、NFT,以及一些靠概念包裝的GameFi、SocailFi等Web3.0賦能場景。但是,如何將數據“AI”化,也就是讓“區塊鏈”讀懂現實世界的預言,並加於場景生態賦能化。預言機,便顯得舉足輕重,猶如當下的ChatGPT。
我們都知道預言機和區塊鏈的關係非常密切。在區塊鏈中,智能合約可以執行各種操作,例如資金管理、數據存儲等。然而,智能合約並不知道現實世界中發生的事件,這就需要預言機。因為預言機是連接現實世界和區塊鏈的數據橋樑,可以將現實世界中發生的事件轉化為可用於智能合約的數據。
簡單來說,預言機能讓確定的智能合約對不確定的外部世界做出“反應”。而ChatGPT不就是對訪問的數據做出與之對應的“反應”?
其中,預言機的主要功能是獲取並驗證外部數據,並將其輸入到區塊鏈中。它們可以採用多種方式獲取數據,例如API、傳感器、網絡爬蟲等。在驗證數據方面,預言機需要保證數據的真實性和準確性。
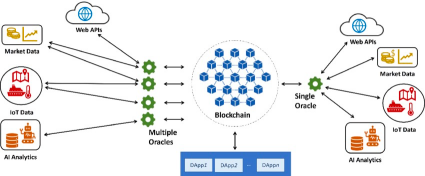
因此,預言機必須經過精心設計和測試,以確保數據的可靠性。這些驗證過程可能包括數字簽名、加密算法等。但預言機的發展也面臨著一些挑戰,其中最大的挑戰之一是確保數據的可靠性。預言機需要獲取大量數據,並對其進行驗證。
如果把區塊鏈比做一個“黑匣子”,那麼預言機就是黑暗中的一束光,照亮著比特世界。
當然了,當前的區塊鏈生態仍舊是發展的初級階段,較之傳統行業,除了在金融領域稍有建樹外,其它地方仍稍顯貧瘠。對於其數據的利用、調取、挖掘、分析,仍需很長一段時間去發展。
雖然市場湧現了不少像ChainLink、PlugChain、Oraclize、UMA、DIA 、API3這樣的主流預言機公鏈,它們各在技術領域都有著各自的突破和創新,但細觀生態發展、場景賦能、商業落地,依舊還有很長一段路要走。
這就像是,如果ChatGPT需要更智能,就需要更多、更大規模的數據訓練。如果區塊鏈世界需要更智能,就需要預言機的數據讀取、傳送、抓取更精準、更高效。
同時,在更去中心化問題上,單源API 很容易被破解和操作,中心化預言機顯得有些雞肋。因此,像ChainLink、PlugChain、NEST等這種主打去中心化預言機網絡的節點抓取數據的準確率更高些。因為他們的網絡節點是則從多個來源拉取數據,通過數據聚合加權大大降低了數據的錯誤率。
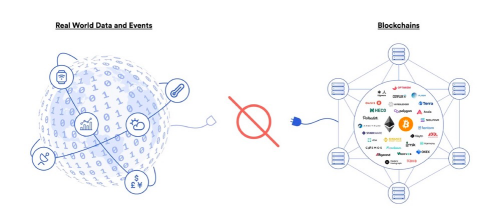
總之,預言機作為一座連接物理世界和區塊世界的數據橋樑,具有重要的意義和潛力。它們不僅可以幫助智能合約更好地執行各種任務,並解決現實世界中的問題。同時,隨著技術的進步和應用場景的擴大,預言機的未來將會更加廣闊。
結語:最後,當我們去對比ChatGPT和預言機兩者時不難發現一個核心點:兩者存在的價值都是對“數據價值”的提煉,對“數據生態”的賦能,對“場景落地”的驅動。唯一不同的是,一個是在Web2.0,一個是在Web3.0。伴隨著技術的日新月異,Web2.0和Web3.0的邊界會越來越模糊,當預言機將物理世界的數據接入到比特世界中,以ChatGPT為代表的AI算力去不斷挖掘“數據潛力”。
到那時,Web3.0的生態恐怕不再貧瘠、不再單調,和我們現實世界無異,那才是真正的Metaverse。












