如果說元宇宙是“數字化”的終極形態,那動捕技術則是實現人“數字化”的關鍵一步。

在影視製作中,動作捕捉是最常用到的一項技術。無論是《阿凡達》還是《指環王》裡的咕嚕,都是先利用動作捕捉採集演員的肢體表演,再將捕捉到的動作渲染處理後,才呈現出震撼的視覺效果。
遊戲行業也是動捕技術的核心應用場景。遊戲動畫中包含很多複雜的姿勢動作,通過採集真人演員的動作數據,綁定到遊戲角色的骨骼上,可以最大程度地還原人體真實的姿態、表情、重量和速度,從而讓玩家能夠體驗到更加真實的遊戲世界。
隨著“元宇宙”概念的全面普及,動作捕捉對元宇宙的長期價值也逐漸顯現出來,它和引擎、 傳輸、計算和顯示等技術處於同一級別,是元宇宙底層建設這塊“巨大拼圖”中的重要一塊。
動捕技術發展歷程
類似動作捕捉的技術最早出現在1915年,當時的動畫大師Max Fleischer 製作了一台放映機,原理就是把膠片的內容顯示到透光台上。憑藉著這台放映機,動畫師可以很方便地照著畫面中人物的動作造型,來繪製角色動作。
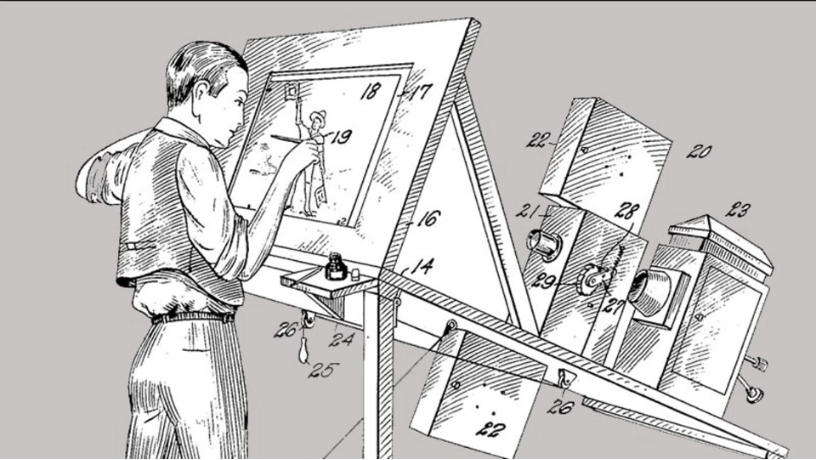
圖| 繪畫放映機
1983年,加拿大思蒙弗雷澤大學的Tom Calvert在物理機械捕捉服裝上取得的重大突破,這一技術讓人們見識到了最早的機械類捕捉。與此同時,麻省理工也推出了一套基於LED的“木偶圖像化(graphical marionetter)”系統,這就是早期光學動捕系統的雛形。
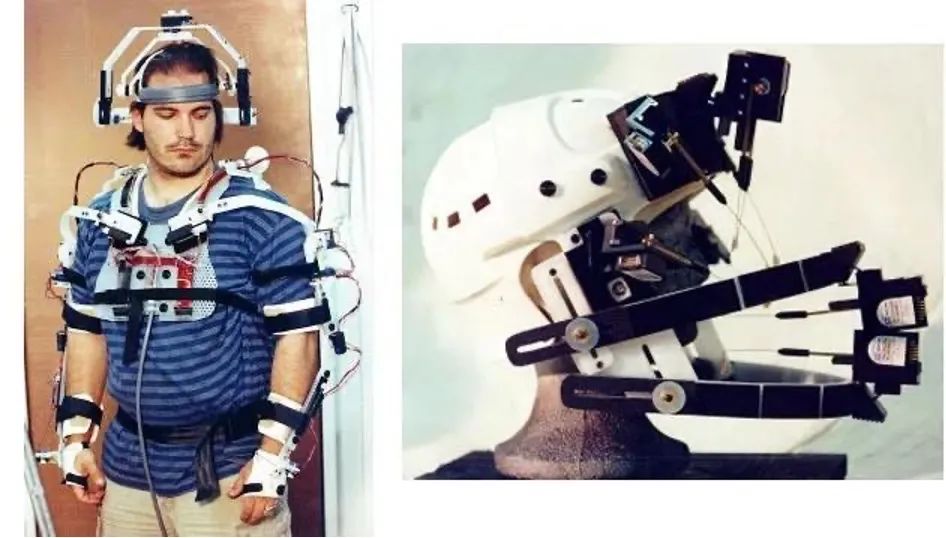
圖| Tom Calvert研究成果
此番生物力學研究為未來的影片製作鋪平了道路,在接下來的時間裡,當動作捕捉與計算機圖形技術相遇,動作數據的易得性使動作捕捉技術快速發展,並相繼被完整、大規模地運用到遊戲與電影行業。
90年末,電影《指環王》的拍攝則第一次將動捕拍攝步驟帶到了拍攝現場,動捕演員先驅Andy Serkis在場地中可以作為“咕嚕”這一角色和其他演員進行互動,這樣的互動更加有利於角色的塑造,因為只有當演員在表演過程中獲得了其他演員的情緒和語言反饋,自身情緒才能更酣暢地被釋放,角色才能更加有血有肉、活靈活現。

圖| 電影《指環王》動作捕捉劇照
2009年上映的電影《阿凡達》可以說是將動作捕捉與表情捕捉技術成功結合的先驅者。導演James Cameron與團隊使用了頭戴式面部捕捉相機,並建立了有史以來最大的拍攝與動作捕捉影棚。

圖| 電影《阿凡達》動作捕捉劇照
特效影視製作和遊戲從來是不分家的,很快有人把動作捕捉的概念帶到了遊戲圈。在這個領域最具有先鋒意識的是當時在主機領域與任天堂、索尼三分天下的世嘉。
它1994年推出的街機遊戲《VR戰士》就使用了動作捕捉模擬人物行動。這種新概念在當時粗糙的街機和家用機遊戲市場成為一股清流,用逼真流暢的動作嚇呆了一眾玩家。隔年,南夢宮也推出了《刀魂》,作為自家動作捕捉技術的先鋒軍,也取得了成功。
如今,動作捕捉幾乎成為大型遊戲工作室標配,利用動捕技術,真人和動畫人物是同步的,遊戲角色會顯得更加真實、生動。這就是為什麼我們可以在遊戲中看到電影級水平的動作表演。
常見的動捕技術
隨著技術的成熟,現在動作捕捉技術應用的領域也越來越廣泛了,從動畫製作、人機交互、到機器人遙控、體育訓練等等,甚至現在的虛擬人直播,也是用的動捕技術。
面對不同的使用場景,動捕技術也出現了多種技術路線,常見的有光學動作捕捉技術、慣性動作捕捉技術以及視覺動作捕捉技術。
光學動作捕捉技術操作的時候會直接在人的身體上進行簡單的標記,標記點會直接反射到提前設定好的攝像機上,然後再通過反射的不同位置的成像信息來預算標記點的空間運動信息,最終將信息進行簡單地定位以及輸出。

圖| 光學動捕:身上標記光點
慣性動作捕捉技術會直接在人的身上佩戴陀螺儀,人在運動的時候,陀螺儀也會跟著進行旋轉。此時,直接通過感知陀螺儀的旋轉信息將人的運動推算出,然後實現動作捕捉。
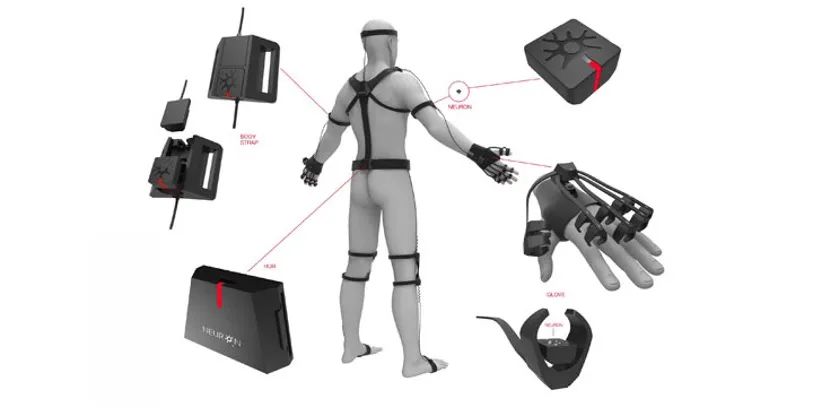
圖| 慣性動捕需穿戴各種設備
視覺動作捕捉技術在操作的時候是不需要標記和佩戴設備的,只要在人的活動範圍內通過普通的攝像頭進行動作的錄製,將人體關鍵信息進行識別,然後採用特殊AI算法實現動作捕捉。

圖| AI引擎驅動的動捕技術
光學動作捕捉技術和慣性動作捕捉技術有一定的使用門檻,在影視和遊戲領域比較常見,雖然呈現的效果非常精準,但存在兩個問題:第一,成本高。便宜的至少也需要幾萬,貴的則需要幾十萬至幾百萬不等,只有大型影視和遊戲工作室才能負擔得起這種成本。第二,使用不方便。在製作現場,動捕演員身上往往穿戴很多設備,穿戴設備與動作捕捉需要團隊多人配合。
而更便於在普通消費者市場進行普及的視覺動作捕捉技術,近年來受到蘋果、Meta等大廠的追逐。
Meta用一個頭顯搞定全身動捕
早在2019年,Meta就曾公佈其虛擬人頭像系統,其特點是通過VR設備進行3D動捕技術來還原真人形象,可渲染出高度保真的膚色、紋理、毛髮、微表情等細節。 Meta希望未來人們在虛擬環境中見面就像在現實中一樣真實。

圖| Meta旗下VR設備Quest可識別面部表情
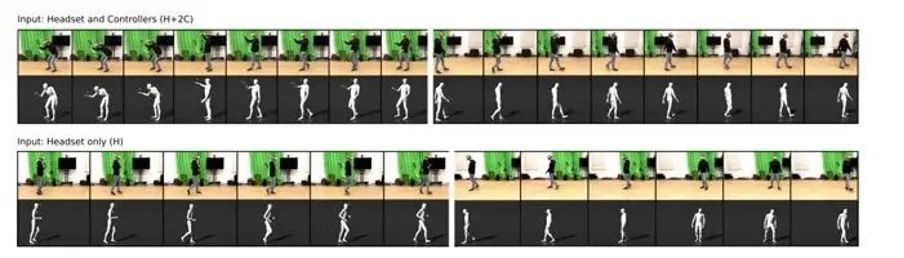
據外媒報導,根據本月發布的一份論文,Meta提出了一種僅通過Quest實現全身動捕的解決方案。也就是說, 此前VR頭顯僅僅可以將面部表情進行動作捕捉,而現在已經可以實現全身動作捕捉。
這主要是由人工智能的預測能力所驅動的。
對於上半身追踪,通過在AI訓練過程中獲得的經驗,僅需來自現實世界的少量輸入就足以將雙手準確地轉換到虛擬世界。例如,Quest的攝像頭可以看到你的手臂,肘部,手掌,所以可以很好地根據肌肉骨骼結構估計上半身的完整姿態。

圖| Quest頭顯可實現全身動作捕捉
現在對於下半身,Meta同樣在探索利用這一原理。使用收集的追踪數據訓練人工智能,僅使用來自VR頭顯和兩個控制器的傳感器數據,就可以逼真地製作全身虛擬人動畫。
Meta團隊使用人工生成的傳感器數據訓練QuestSim (AI引擎)。為此,研究人員根據172人各8小時的運動捕捉剪輯模擬了頭顯和控制器的運動。這樣,他們就不必從頭開始捕捉頭顯和控制器與身體運動的數據。
動作捕捉剪輯包括130分鐘的步行、110分鐘的慢跑、80分鐘的手勢、對話、90分鐘的白板討論和70分鐘的保持平衡。
圖| AI引擎自我學習中
訓練後,QuestSim可以根據真實的頭顯和控制器數據識別出一個人正在執行的動作。利用人工智能預測,QuestSim甚至可以模擬沒有實時傳感器數據的身體部位運動。
研究人員還進一步發現,即使不用手柄控制器,只需要頭顯的60個姿勢(包含位置和方向數據),就足以重建各種運動姿態,還原出來的效果同樣沒有物理偽影(本不存在卻出現在影像中的成像)。
對於動捕技術的未來,中信證券認為,動捕技術有望在生物力學、工程應用、遊戲、影視、VR等方向進一步發展和應用。在元宇宙發展的過程中,捕捉用戶動作並及時生成虛擬世界中的相應表現是用戶高質量體驗的重要一環,將來動作捕捉將有廣泛的基礎應用空間。

中文推特: https://twitter.com/8BTC_OFFICIAL