

撰文:Vitalik Buterin
編輯:Kate,MarsBit
這篇文章主要針對大致熟悉2019 年時代密碼學的讀者,特別是SNARK 和STARK。如果你不是,我建議你先閱讀這些文章。特別感謝Justin Drake, Jim Posen, Benjamin Diamond 和Radi Cojbasic 的回饋和評論。
在過去的兩年中,STARK 已經成為一種關鍵且不可替代的技術,可以有效地對非常複雜的語句進行易於驗證的加密證明(例如,證明以太坊區塊是有效的)。其中一個關鍵原因是欄位大小小:基於橢圓曲線的SNARK 要求您在256 位元整數上工作才能足夠安全,而STARK 允許您使用更小的欄位大小,效率更高:首先是Goldilocks 欄位(64 位元整數) ,然後是Mersenne31 和BabyBear(都是31 位元)。由於這些效率的提高,使用Goldilocks 的Plonky2 在證明多種計算方面比其前輩快數百倍。
一個自然而然的問題是:我們能否將這一趨勢引向合乎邏輯的結論,透過直接在零和一上操作來建立運行速度更快的證明系統?這正是Binius 試圖做的事情,使用了許多數學技巧,使其與三年前的SNARK 和STARK 截然不同。這篇文章介紹了為什麼小字段使證明生成更有效率,為什麼二進位字段具有獨特的強大功能,以及Binius 用來使二進製字段上的證明如此有效的技巧。
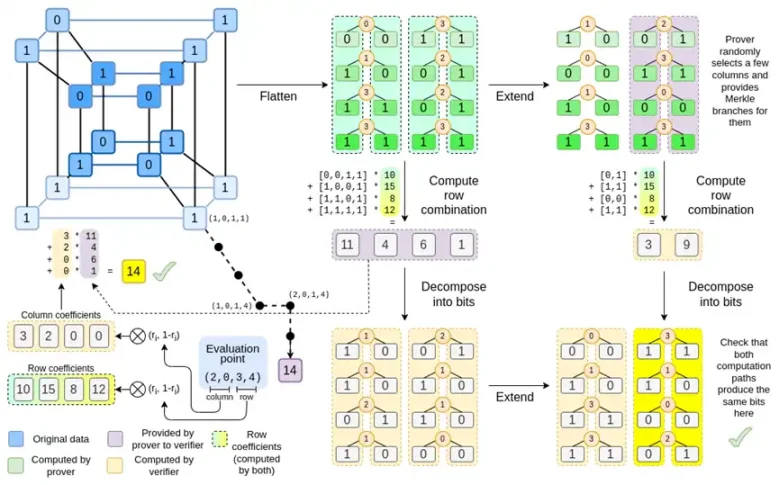
Binius,在這篇文章的最後,你應該可以理解此圖的每個部分。
回顧:有限域(finite fields)
加密證明系統的關鍵任務之一是對大量資料進行操作,同時保持數字較小。如果你可以將一個關於大型程式的語句壓縮成一個包含幾個數字的數學方程,但是這些數字與原始程式一樣大,那麼你將一無所獲。
為了在保持數字較小的情況下進行複雜的算術,密碼學家通常使用模運算(modular arithmetic)。我們選擇一個質數“模數”p。 % 運算子的意思是「取餘數」:15%7=1,53%10=3,等等。 (請注意,答案總是非負數的,所以例如-1%10=9)

你可能已經在時間的加減上下文中見過模運算( 例如,9 點過4 小時是幾點?但在這裡,我們不只是對某個數進行加、減模,我們還可以進行乘、除和取指數。
我們重新定義:
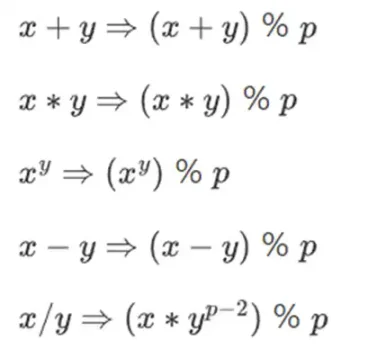
以上規則都是自洽的。例如,如果p=7,那麼:
5+3=1(因為8%7=1)
1-3=5(因為-2%7=5)
2*5=3
3/5=2
這種結構的更通用術語是有限域。有限域是一種數學結構,它遵循通常的算術法則,但其中可能的值數量有限,因此每個值都可以用固定的大小表示。
模運算( 或質數域) 是有限域最常見的類型,但也有另一種類型:擴展域。你可能已經看過一個擴充字段:複數。我們「想像」一個新元素,並給它貼上標籤i,並用它進行數學運算:(3i+2)*(2i+4)=6i*i+12i+4i+8=16i+2。我們可以同樣地取質數域的擴展。當我們開始處理較小的字段時,質數字段的擴展對於保護安全性變得越來越重要,而二進製字段(Binius 使用) 完全依賴於擴展以具有實際效用。
回顧:算術化
SNARK 和STARK 證明電腦程式的方法是透過算術:你把一個關於你想證明的程式的陳述,轉換成一個包含多項式的數學方程式。方程式的有效解對應於程式的有效執行。
舉個簡單的例子,假設我計算了第100 個斐波那契數,我想向你證明它是什麼。我建立了一個編碼斐波那契數列的多項式F:所以F(0)=F(1)=1、F(2)=2、F(3)=3、F(4)=5 依此類推,共100 步。我需要證明的條件是F(x+2)=F(x)+F(x+1) 在整個範圍內x={0,1…98}。我可以透過給你商數來說服你:
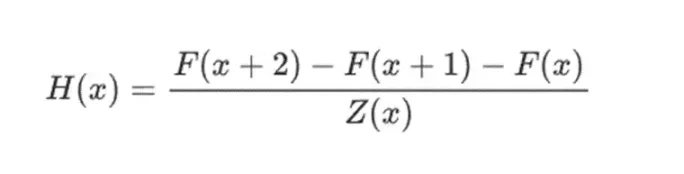
其中Z(x) = (x-0) * (x-1) * …(x-98)。 . 如果我能提供有F 且H 滿足此等式,則F 必須在該範圍內滿足F(x+2)-F(x+1)-F(x)。如果我另外驗證滿足F,F(0)=F(1)=1,那麼F(100) 其實必須是第100 個斐波那契數。
如果你想證明一些更複雜的東西,那麼你用一個更複雜的方程式來取代「簡單」關係F(x+2) = F(x) + F(x+1),它基本上是說「F( x+1) 是初始化一個虛擬機器的輸出,狀態是F(x)”,並且運行一個計算步驟。你也可以用一個更大的數字來代替數字100,例如,100000000,以容納更多的步驟。
所有SNARK 和STARK 都基於這個想法,即使用多項式( 有時是向量和矩陣) 上的簡單方程式來表示單一值之間的大量關係。並非所有的演算法都像上面那樣檢查相鄰計算步驟之間的等價性:例如,PLONK 沒有,R1CS 也沒有。但是許多最有效的檢查都是這樣做的,因為多次執行相同的檢查( 或相同的少數檢查) 可以更輕鬆地將開銷降至最低。
Plonky2:從256 位元SNARK 和STARK 到64 位元...... 只有STARK
五年前,不同類型的零知識證明的合理總結如下。有兩種類型的證明:( 基於橢圓曲線的)SNARK 和( 基於哈希的)STARK。從技術上講,STARK 是SNARK 的一種,但在實踐中,通常使用“SNARK”來指基於橢圓曲線的變體,而使用“STARK”來指基於哈希的結構。 SNARK 很小,因此你可以非常快速地驗證它們並輕鬆地將它們安裝在鏈上。 STARK 很大,但它們不需要可信的設置,而且它們是抗量子的。
STARK 的工作原理是將數據視為多項式,計算該多項式的計算,並使用擴展數據的梅克爾根作為「多項式承諾」。
這裡的一個關鍵歷史是,基於橢圓曲線的SNARK 首先得到了廣泛的使用:直到2018 年左右,STARK 才變得足夠高效,這要歸功於FRI,而那時Zcash 已經運行了一年多。基於橢圓曲線的SNARK 有一個關鍵的限制:如果你想使用基於橢圓曲線的SNARK,那麼這些方程式中的算術就必須使用橢圓曲線上的點數模數來完成。這是一個很大的數字,通常接近2 的256 次方:例如,bn128 曲線為2188824287183927522224640574525727508854836440041603434369820885483644004160343436982018854836440041603434369820194369820。但實際的計算使用的是小數字:如果你用你最喜歡的語言來考慮一個“真正的”程序,它使用的大部分東西是計數器,for 循環中的索引,程序中的位置,代表True 或False 的單一位,以及其他幾乎總是只有幾位數長的東西。
即使你的「原始」資料由「小」數字組成,證明過程也需要計算商數、擴展、隨機線性組合和其他資料轉換,這將導致相等或更大數量的對象,這些對象的平均大小與你的字段的全部大小一樣大。這造成了一個關鍵的低效率:為了證明對n 個小值的計算,你必須對n 個大得多的值進行更多的計算。起初,STARK 繼承了SNARK 使用256 位元欄位的習慣,因此也遭受了同樣的低效率。

一些多項式求值的Reed-Solomon 擴充功能。儘管原始值很小,但額外的值都將擴展到字段的完整大小( 在本例中是2 的31 次方-1)
2022 年,Plonky2 發布。 Plonky2 的主要創新是對一個較小的質數進行算術取模:2 的64 次方– 2 的32 次方+ 1 = 18446744067414584321。現在,每次加法或乘法總是可以在CPU 上的幾個指令中完成,並且將所有資料哈希在一起的速度比以前快4 倍。但這有一個問題:這種方法只適用於STARK。如果你嘗試使用SNARK,對於如此小的橢圓曲線,橢圓曲線將變得不安全。
為了確保安全,Plonky2 還需要引入擴充字段。檢查算術方程式的一個關鍵技術是「隨機點抽樣」:如果你想檢查的H(x) * Z(x) 是否等於F(x+2)-F(x+1)-F(x),你可以隨機選擇一個座標r,提供多項式承諾開證明證明H(r)、Z(r) 、F(r),F(r+1) 和F(r+2),然後驗證H(r) * Z(r) 是否等於F(r+2)-F(r+1)- F(r)。如果攻擊者可以提前猜出座標,那麼攻擊者就可以欺騙證明系統——這就是為什麼證明系統必須是隨機的。但這也意味著座標必須從一個足夠大的集合中採樣,以使攻擊者無法隨機猜測。如果模數接近2 的256 次方,這顯然是事實。但是,對於模數是2 的64 次方-2 的32 次方+1,我們還沒到那一步,如果我們降到2 的31 次方-1,情況肯定不是這樣。試圖偽造證明20 億次,直到一個人幸運,這絕對在攻擊者的能力範圍內。
為了阻止這種情況,我們從擴展字段中採樣r,例如,你可以定義y,其中y 的3 次方=5,並採用1、y、y 的2 次方的組合。這將使座標的總數增加到大約2 的93 次方。證明者計算的多項式的大部分不進入這個擴展域;只是用整數取模2 的31 次方-1,因此,你仍然可以從使用小域中獲得所有的效率。但是隨機點檢查和FRI 計算確實深入到這個更大的領域,以獲得所需的安全性。
從小質數到二進制數
計算機透過將較大的數字表示為0 和1 的序列來進行算術運算,並在這些bit 之上建構「電路」來計算加法和乘法等運算。計算機特別針對16 位元、32 位元和64 位元整數進行了最佳化。例如,2 的64 次方-2 的32 次方+1 和2 的31 次方-1,選擇它們不僅是因為它們符合這些界限,還因為它們與這些界限很吻合:可以透過執行常規的32 位乘法來執行乘法取模2 的64 次方-2 的32 次方+1,並在幾個地方按位移位和複製輸出;這個文章很好地解釋了一些技巧。
然而,更好的方法是直接用二進制進行計算。如果加法可以「只是」異或,而無需擔心「攜帶」從一個位元添加1 + 1 到下一個位的溢出?如果乘法可以以同樣的方式更加並行化呢?這些優點都是基於能夠用一個bit 表示真/ 假值。
取得直接進行二進位計算的這些優點正是Binius 試圖要做的。 Binius 團隊在zkSummit 的演講中展現了效率提升:
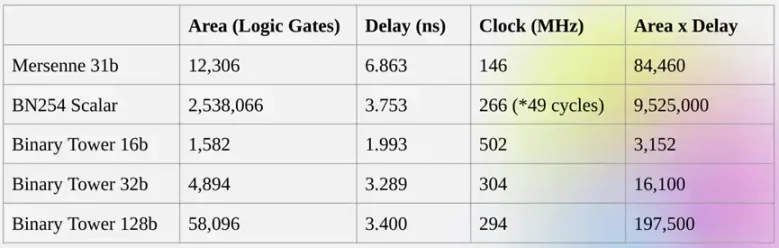
儘管「大小」大致相同,但32 位元二進位字段操作比31 位元Mersenne 字段操作所需的計算資源少5 倍。
從一元多項式到超立方體
假設我們相信這個推理,並且想要用bit(0 和1) 來做所有的事情。我們如何用一個多項式來表示十億bit 呢?
在這裡,我們面臨兩個實際問題:
1. 對於一個表示大量值的多項式,這些值需要在多項式的求值時可以訪問:在上面的斐波那契例子中,F(0),F(1) … F(100),在一個更在大的計算中,指數會達到數百萬。我們使用的欄位需要包含到這個大小的數字。
2. 證明我們在Merkle 樹中提交的任何值( 就像所有STARK 一樣) 都需要Reed-Solomon 對其進行編碼:例如,將值從n 擴展到8n,使用冗餘來防止惡意證明者通過在計算過程中偽造一個值來作弊。這也需要有一個足夠大的字段:要將一百萬個值擴展到800 萬個,你需要800 萬個不同的點來計算多項式。
Binius 的一個關鍵想法是分別解決這兩個問題,並透過以兩種不同的方式表示相同的資料來實現。首先,多項式本身。基於橢圓曲線的SNARK、2019 時代的STARK、Plonky2 等系統通常處理一個變數上的多項式:F(x)。另一方面,Binius 從Spartan 協議中獲得靈感,並使用多元多項式:F(x1,x2,… xk)。實際上,我們在計算的「超立方體」上表示整個計算軌跡,其中每個xi 不是0 就是1。例如,如果我們想要表示一個斐波那契數列,並且我們仍然使用一個足夠大的字段來表示它們,我們可以將它們的前16 個數列想像成這樣:
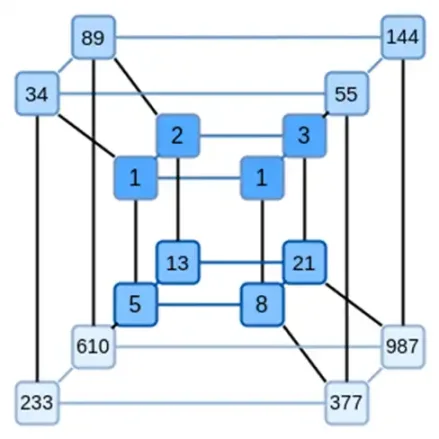
也就是說,F(0,0,0,0) 應該是1,F(1,0,0,0) 也是1,F(0,1,0,0) 是2,以此類推,一直到F(1,1,1,1)=987。給定這樣一個計算的超立方體,就會有一個產生這些計算的多元線性( 每個變數的度數為1) 多項式。所以我們可以把這組值看成是多項式的代表;我們不需要計算係數。
這個例子當然只是為了說明:在實踐中,進入超立方體的全部意義是讓我們處理單一bit。計算斐波那契數的「Binius 原生」方法是使用一個高維的立方體,使用每組例如16 位元儲存一個數字。這需要一些聰明才智來在bit 的基礎上實現整數相加,但對於Binius 來說,這並不太難。
現在,我們來看看糾刪碼。 STARK 的工作方式是:你取n 值,Reed-Solomon 將它們擴展到更多的值( 通常8n,通常在2n 和32n 之間),然後從擴展中隨機選擇一些Merkle 分支,並對它們執行某種檢查。超立方體在每個維度上的長度為2。因此,直接擴展它是不實際的:沒有足夠的“空間”從16 個值中採樣Merkle 分支。那我們該怎麼做呢?我們假設超立方體是一個正方形!
簡單的Binius - 一個例子
請參閱此處查看該協定的python 實作。
讓我們看一個範例,為了方便起見,使用正規整數作為我們的欄位( 在實際實作中,將使用二進位欄位元素)。首先,我們將想要提交的超立方體,編碼為正方形:
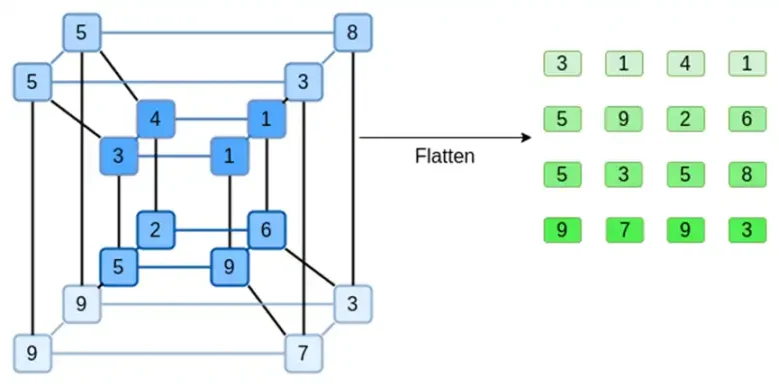
現在,我們用Reed-Solomon 擴展正方形。也就是說,我們將每一行視為在x ={0,1,2,3} 處求值的3 次多項式,並在x ={4,5,6,7} 處求值相同的多項式:
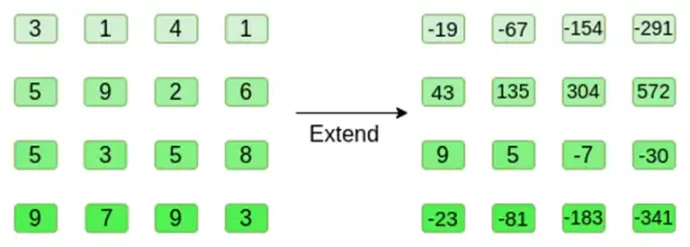
注意,數字會迅速膨脹!這就是為什麼在實際實作中,我們總是使用有限域,而不是正規整數:如果我們使用整數模11,例如,第一行的擴展將只是[3,10,0,6]。
如果你想嘗試擴充功能並親自驗證這裡的數字,可以在這裡使用我的簡單Reed-Solomon 擴充程式碼。
接下來,我們將此擴充視為列,並建立列的Merkle 樹。梅克爾樹的根是我們的承諾。
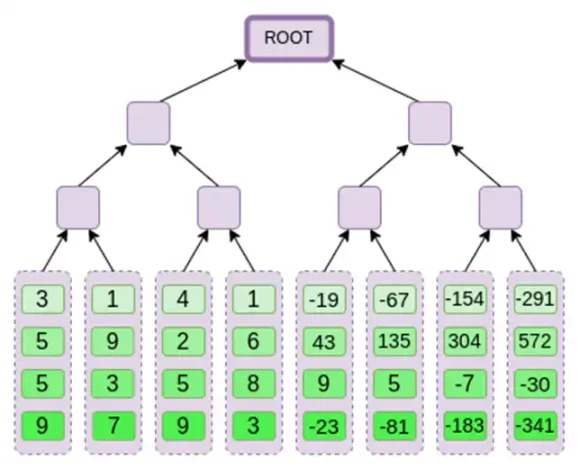
現在,讓我們假設證明者想要在某個時候證明這個多項式的計算r={r0,r1,r2,r3}。在Binius 中有一個細微的差別,使它比其他多項式承諾方案更弱:證明者在提交到Merkle 根之前不應該知道或能夠猜測s ( 換句話說,r 應該是一個依賴於默克爾根的偽隨機值)。這使得該方案對「資料庫查找」無用( 例如,「好吧,你給了我默克爾根,現在證明給我看P(0,0,1,0)!」)。但是我們實際使用的零知識證明協議通常不需要「資料庫查找」;他們只需要在一個隨機的求值點檢查多項式。因此,這個限制符合我們的目的。
假設我們選擇r={1,2,3,4} ( 此時多項式的計算結果為-137;你可以使用此程式碼進行確認)。現在,我們進入了證明的過程。我們分成r 兩部分:第一部分{1,2} 表示行內列的線性組合,第二部分{3,4} 表示行的線性組合。我們計算一個「張量積」,對於列部分:
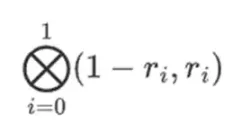
對於行部分:
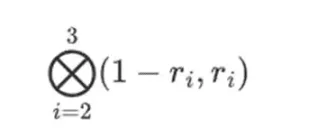
這意味著:每個集合中一個值的所有可能乘積的清單。在行情況下,我們得到:
[(1-r2)*(1-r3), (1-r3), (1-r2)*r3, r2*r3]
利用r={1,2,3,4} ( 所以r2=3 和r3=4):
[(1-3)*(1-4), 3*(1-4),(1-3)*4,3*4] = [6, -9 -8 -12]
現在,我們透過採用現有行的線性組合來計算一個新的「行」t。也就是說,我們取:
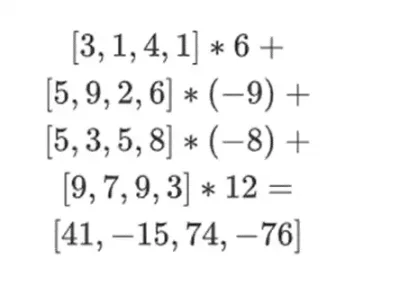
你可以把這裡發生的看作是部分求值。如果我們把全張量乘積乘以所有值的全向量,你將得到計算P(1,2,3,4) = -137。在這裡,我們將只使用一半評估座標的偏張量乘積相乘,並將N 值網格簡化為一行根N 的值。如果你把此行提供給其他人,他們可以用另一半的求值座標的張量積來完成剩下的計算。
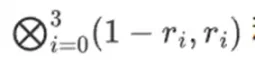
證明者向驗證者提供以下新行:t 以及一些隨機抽樣列的Merkle 證明。在我們的說明性範例中,我們將讓證明程式只提供最後一列;在現實生活中,證明者需要提供數十列來實現足夠的安全性。
現在,我們利用Reed-Solomon 程式碼的線性。我們使用的關鍵屬性是:取一個Reed-Solomon 擴充的線性組合得到與線性組合的Reed-Solomon 擴充相同的結果。這種「順序獨立性」通常發生在兩個操作都是線性的情況下。
驗證者正是這樣做的。他們計算了t,並且計算與證明者之前計算的相同的列的線性組合( 但只計算證明者提供的列),並驗證這兩個過程是否給出相同的答案。
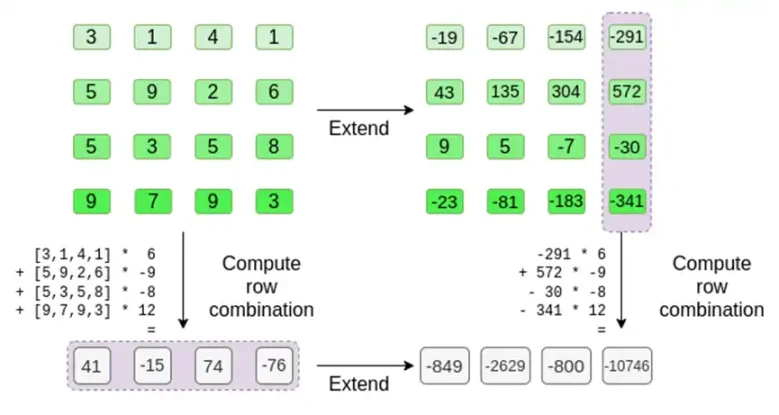
在本例中,是擴展t,計算相同的線性組合([6,-9,-8,12],兩者給出了相同的答案:-10746。這證明默克爾的根是“善意”建構的( 或至少「夠接近」),而且它是符合t 的:至少絕大多數列是相互相容的。
但驗證者還需要檢查另一件事:檢查多項式{r0…r3} 的求值。到目前為止,驗證者的所有步驟實際上都沒有依賴證明者聲稱的值。我們是這樣檢查的。我們取我們標記為計算點的「列部分」的張量積:
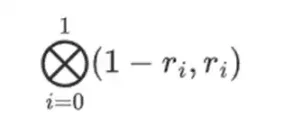
在我們的例子中,其中r={1,2,3,4} 所以選擇列的一半是{1,2}),這等於:
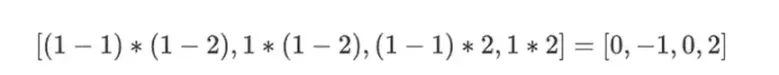
現在我們取這個線性組合t:
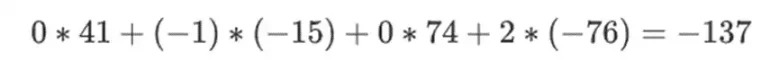
這和直接求多項式的結果是一樣的。
以上內容非常接近「簡單」Binius 協議的完整描述。這已經有了一些有趣的優點:例如,由於資料被分成行和列,因此你只需要一個大小減半的欄位。但是,這並不能實現用二進制進行計算的全部好處。為此,我們需要完整的Binius 協定。但首先,讓我們更深入地了解二進位字段。
二進位字段
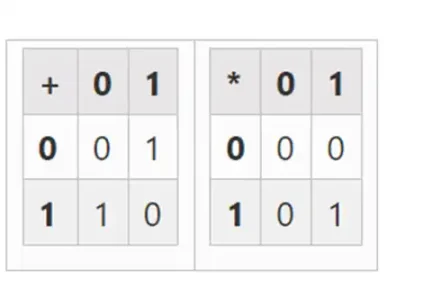
最小的可能域是算術模2,它非常小,我們可以寫出它的加法和乘法表:
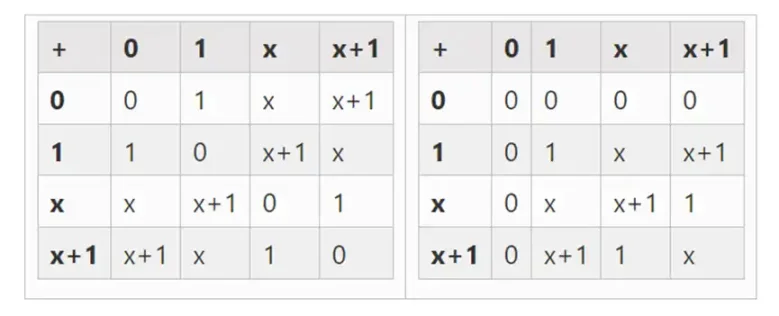
我們可以透過擴展得到更大的二進位字段:如果我們從F2( 整數模2) 然後定義x 在哪裡x 的平方=x+1,我們得到以下的加法和乘法表:
事實證明,我們可以透過重複這個構造將二進位字段擴展到任意大的大小。與實數上的複數不同,在實數上,你可以加一個新元素,但不能再添加任何元素I(四元數確實存在,但它們在數學上很奇怪,例如:ab 不等於ba),使用有限的字段,你可以永遠添加新的擴充。具體來說,我們對元素的定義如下:
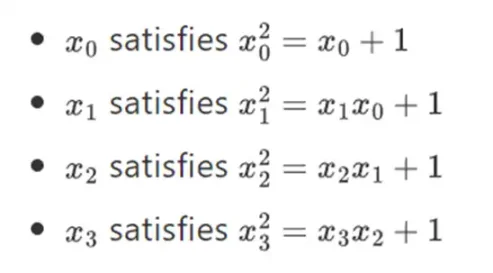
等等......。這通常被稱為塔式結構,因為每一個連續的擴展都可以被視為為塔增加了一個新的層。這並不是構造任意大小二進位字段的唯一方法,但它有一些獨特的優點,Binius 利用了這些優點。
我們可以把這些數字表示成bit 的清單。例如,1100101010001111。第一位表示1 的倍數,第二位表示x0 的倍數,然後後續位元表示以下x1 數的倍數: x1, x1*x0, x2, x2*x0, 依此類推。這種編碼很好,因為你可以分解它:
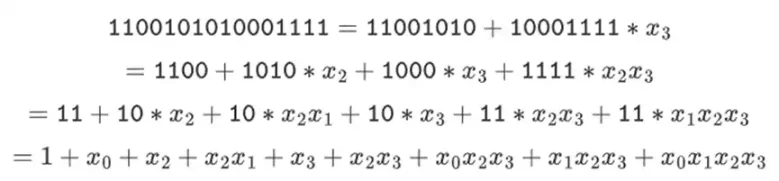
這是一種相對不常見的表示法,但我喜歡將二進位字段元素表示為整數,採用更有效bit 在右側的位表示。也就是說,1=1,x0=01=2,1+x0=11=3,1+x0+x2=11001000 =19, 等等。在這個表達式中,是61779。
二進位字段中的加法只是異或( 順便說一句,減法也是如此);注意,這意味著x+x=0 對於任何x。將兩個元素x*y 相乘,有一個非常簡單的遞歸演算法:把每個數字分成兩半:
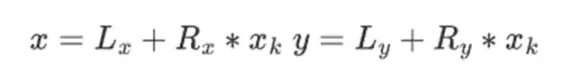
然後,將乘法拆分:
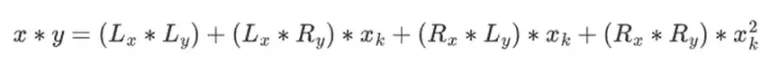
最後一部分是唯一有點棘手的,因為你必須應用簡化規則。有更有效的方法來做乘法,類似於Karatsuba 演算法和快速傅立葉變換,但我將把它作為一個練習留給有興趣的讀者去弄清楚。
二進位字段中的除法是透過結合乘法和反轉來完成的。 「簡單但緩慢」的反轉方法是廣義費馬小定理的應用。還有一個更複雜但更有效的反演演算法,你可以在這裡找到。你可以使用這裡的程式碼來玩二進位字段的加法,乘法和除法。
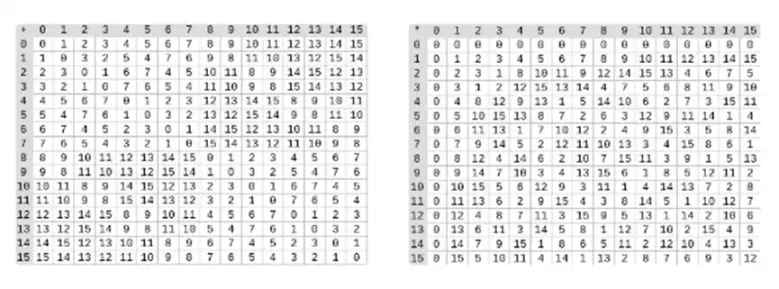
左圖:四位二進位字段元素(即僅由1、x0、x1、x0x1)的加法表。右圖:四位二進位字段元素的乘法表。
這種類型的二進位字段的美妙之處在於,它結合了“正則”整數和模運算的一些最好的部分。與正規整數一樣,二進位字段元素是無界的:你可以隨意擴展。但就像模運算一樣,如果你在一定的大小限制內對值進行運算,你所有的結果也會保持在相同的範圍內。例如,如果取42 連續冪,則得到:
255 步之後,你就回到42 的255 次方=1,就像正整數和模運算一樣,它們遵循通常的數學定律:a*b=b*a、a*(b+c)=a* b+a*c,甚至還有一些奇怪的新法律。
最後,二進位欄位可以方便地處理bit:如果你用適合2 的k 次方的數字做數學運算,那麼你所有的輸出也將適合2 的k 次方bit。這避免了尷尬。在以太坊的EIP-4844 中,一個blob 的各個「區塊」必須是數位模5243587517512619047944774050818596583769055250052763782260365837690552500527637822603658696938691931378226036檢查,以確保每個元素儲存的值小於2 的248 次方。這也意味著二進位字段運算在電腦上是超級快速的——無論是CPU,還是理論上最優的FPGA 和ASIC 設計。
這一切都意味著我們可以像上面所做的Reed-Solomon 編碼那樣做,以一種完全避免整數“爆炸”的方式,就像我們在我們的例子中看到的那樣,並且以一種非常“原生」的方式,計算機擅長的那種計算。二進位欄位的「拆分」屬性-我們是如何做到的1100101010001111=11001010+10001111*x3,然後根據我們的需求進行拆分,這對於實現很大的靈活性也是至關重要的。
完整的Binius
請參閱此處查看該協定的python 實作。
現在,我們可以進入「完整的Binius」,它將「簡單的Binius」調整為(i) 在二進位欄位上工作,(ii) 讓我們提交單一bit。這個協議很難理解,因為它在查看比特矩陣的不同方式之間來回切換;當然,我花了更長的時間來理解它,這比我通常理解加密協議所花的時間要長。但是一旦你理解了二進位字段,好消息是Binius 所依賴的「更難的數學」就不存在了。這不是橢圓曲線配對,在橢圓曲線配對中有越來越深的代數幾何兔子洞要鑽;在這裡,你只需要二進位字段。
讓我們再看一下完整的圖表:
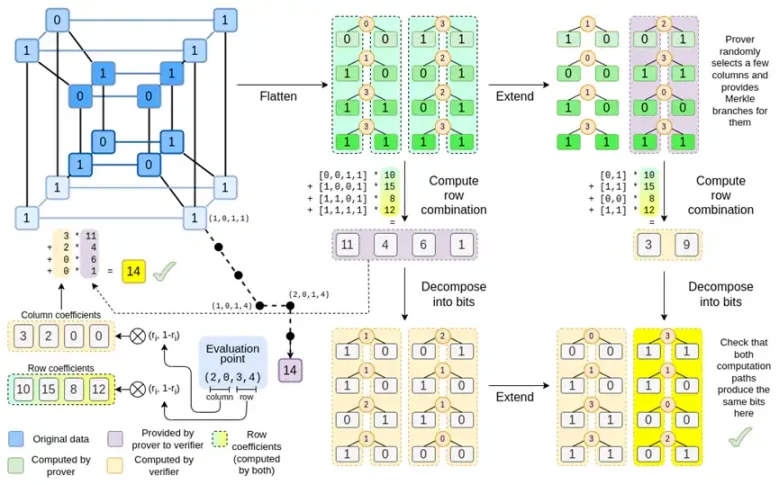
到目前為止,你應該熟悉了大多數組件。將超立方體「扁平化」成網格的思想,將行組合和列組合計算為評價點的張量積的思想,以及檢驗“Reed-Solomon 擴展再計算行組合”和“計算行組合再Reed- Solomon 擴展」之間的等價性的思想,都是在簡單的Binius 中實現的。
「完整的Binius」有什麼新內容?基本上有三件事:
- 超立方體和正方形中的單一值必須是bit(0 或1)。
- 擴充過程透過將bit 分組為列並暫時假定它們是較大的欄位元素,將bit 擴展為更多的bit
- 在行組合步驟之後,有一個元素方面的「分解為bit」步驟,該步驟將擴充轉換回bit
我們將依序討論這兩種情況。首先,新的延期程序。 Reed-Solomon 程式碼有一個基本的限制,如果你要擴充n 到k*n,則需要在具有k*n 不同值的欄位中工作,這些值可以用作座標。使用F2(又稱bit),你無法做到這一點。因此,我們所做的是,將相鄰F2 的元素「打包」在一起形成更大的值。在這裡的範例中,我們一次將兩個bit 打包到{0,1,2,3} 元素中,因為我們的擴充只有四個計算點,所以這對我們來說已經足夠了。在“真實”證明中,我們可能一次返回16 位。然後,我們對這些打包值執行Reed-Solomon 程式碼,並再次將它們解壓縮為bit。
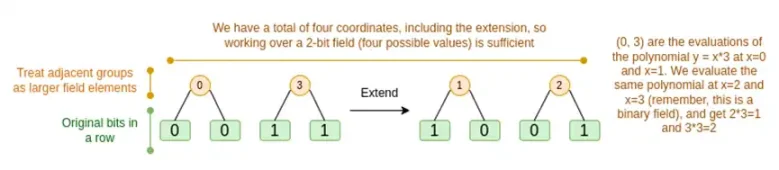
現在,行組合。為了讓「在隨機點求值」檢查加密安全,我們需要從一個相當大的空間( 比超立方體本身大得多) 中對該點進行採樣。因此,雖然超立方體內的點是位,但超立方體外的計算值將會大得多。在上面的例子中,「行組合」最終是[11,4,6,1]。
這就出現了一個問題:我們知道如何將bit 組合成一個更大的值,然後在此基礎上進行Reed-Solomon 擴展,但是如何對更大的值對做同樣的事情呢?
Binius 的技巧是按bit 處理:我們查看每個值的單一bit ( 例如:對於我們標為「11」的東西,即[1,1,0,1] ),然後按行擴展。物件上執行擴充過程。也就是說,我們對每個元素的1 行執行擴展過程,然後在x0 行上,然後在“x1”行上,然後在x0x1 行上,依此類推(好吧,在我們的玩具示例中,我們停在那裡,但在實際實現中,我們將達到128 行(最後一個是x6*…*x0))
回顧:
- 我們把超立方體中的bit,轉換成一個網格
- 然後,我們將每行上的相鄰bit 組視為更大的字段元素,並對它們進行算術運算以Reed-Solomon 擴展行
- 然後,我們取每列bit 的行組合,並得到每一行的bit 列作為輸出( 對於大於4x4 的正方形,要小得多)
- 然後,我們把輸出看成一個矩陣,再把它的bit 當作行
為什麼會這樣呢?在「普通」數學中,如果你開始將一個數字按bit 切片,( 通常) 以任意順序進行線性運算並得到相同結果的能力就會失效。例如,如果我從數字345 開始,我把它乘以8,然後乘以3,我得到8280,如果把這兩個運算反過來,我也得到8280。但如果我在兩個步驟之間插入一個「按bit 分割」操作,它就會崩潰:如果你做8 倍,然後做3 倍,你會得到:
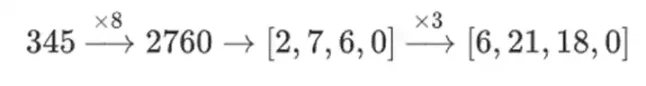
但是,如果你做3 倍,然後做8 倍,你會得到:
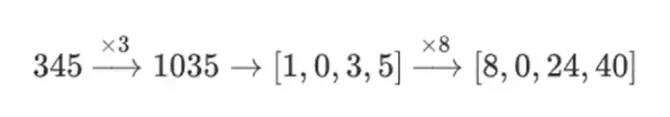
但在用塔結構建構的二進位場中,這種方法確實有效。原因在於它們的可分離性:如果你用一個大的值乘以一個小的值,在每個線段上發生的事情,會留在每個線段上。如果我們1100101010001111 乘以11,這和第一次分解1100101010001111 是一樣的,為
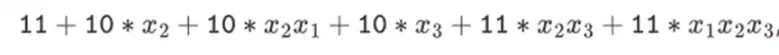
然後將每個分量分別乘以11 相同。
把它們放在一起
一般來說,零知識證明系統的工作原理是對多項式進行陳述,同時表示對底層評估的陳述:就像我們在斐波那契的例子中看到的那樣,F(X+2)-F( X+1)-F(X) = Z(X)*H(X) 同時檢查斐波那契計算的所有步驟。我們透過在隨機點證明求值來檢查關於多項式的陳述。這種隨機點的檢查代表整個多項式的檢查:如果多項式方程式不匹配,則它在特定隨機座標處匹配的可能性很小。
在實踐中,效率低下的一個主要原因是在實際程序中,我們處理的大多數數字都很小:for 迴圈中的索引、True/False 值、計數器和類似的東西。但是,當我們使用Reed-Solomon 編碼「擴展」資料以使基於Merkle 證明的檢查安全所需的冗餘時,大多數「額外」值最終會佔用欄位的整個大小,即使原始值很小。
為了解決這個問題,我們想讓這個場越小越好。 Plonky2 將我們從256 位數字降至64 位數字,然後Plonky3 進一步降至31 位。但即使這樣也不是最優的。使用二進位字段,我們可以處理單一bit。這使得編碼「密集」:如果你的實際底層資料有n 位,那麼你的編碼將有n 位,擴展將有8 * n 位,沒有額外的開銷。
現在,讓我們第三次看這張圖表:
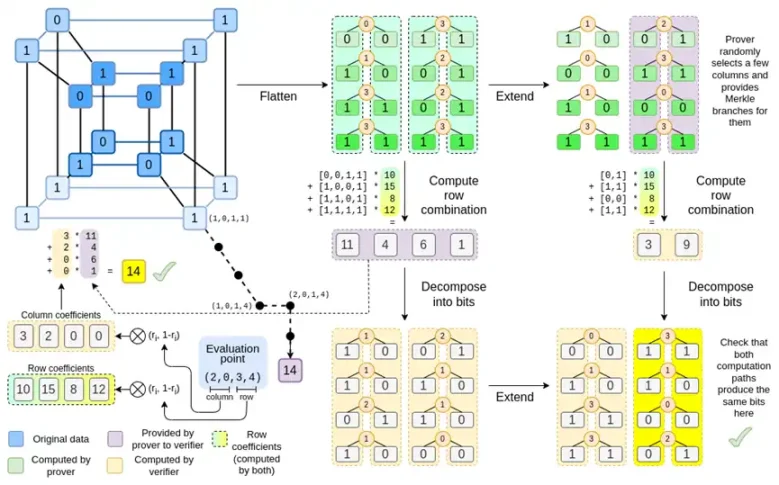
在Binius 中,我們致力於一個多線性多項式:一個超立方體P(x0,x1,…xk),其中單一評估P(0,0,0,0),P(0,0,0,1) 直到P(1,1,1,1), 保存我們關心的資料。為了證明某一點上的計算,我們將相同的數據「重新解釋」為一個平方。然後,我們擴展每一行,使用Reed-Solomon 編碼,為隨機默克爾分支查詢提供安全所需的資料冗餘。然後我們計算行的隨機線性組合,設計係數,使新的組合行實際上包含我們關心的計算值。這個新建立的行( 被重新解釋為128 行bit) 和一些隨機選擇的帶有Merkle 分支的列都被傳遞給驗證者。
然後,驗證器執行「擴展的行組合」( 或者更確切地說,是擴展的幾列) 和「行組合的擴展」,並驗證兩者是否匹配。然後計算一個列組合,並檢查它是否傳回證明者所聲明的值。這就是我們的證明系統( 或者更確切地說,多項式承諾方案,它是證明系統的關鍵組成部分)。
我們還沒講到什麼?
- 有效的演算法來擴展行,這是實際提高驗證器計算效率所必需的。我們在二進位字段上使用快速傅立葉變換,在這裡描述( 儘管確切的實現將有所不同,因為這篇文章使用了一個不基於遞歸擴展的效率較低的結構)。
- 算術化。一元多項式很方便,因為您可以做一些事情,例如F(X+2)-F(X+1)-F(X) = Z(X)*H(X) 將計算中相鄰的步驟連結起來。在超立方體中,「下一步」的解釋遠不如「X+1」。你可以做X+k,k 的冪,但是這種跳躍行為會犧牲Binius 的許多關鍵優勢。 Binius 論文介紹了解決方案。參見第4.3 節),但這本身就是一個「深兔子洞」。
- 如何安全地進行特定值檢查。斐波那契範例需要檢查關鍵邊界條件:F(0)=F(1)=1 和F(100) 的值。但是對於「原始的」Binius,在已知的計算點進行檢查是不安全的。有一些相當簡單的方法可以將已知計算檢查轉換為未知計算檢查,使用所謂的和檢查協議;但是我們這裡沒有講到這些。
- 查找協議,這是另一項最近被廣泛使用的技術,它被用來製作超高效的證明系統。 Binius 可以與許多應用程式的查找協定結合使用。
- 超越平方根驗證時間。平方根是昂貴的:bit 的Binius 證明2 的32 次方大約11MB 長。你可以使用其他證明系統來彌補這個問題,以製作「Binius 證明的證明」,從而獲得Binius 證明的效率和較小的證明大小。另一種選擇是更複雜的FRI- binius 協議,它創建了一個多對數大小的證明( 就像普通的FRI)。
- Binius 是如何影響「SNARK 友善」的。基本的總結是,如果你使用Binius,你不再需要關心如何使計算“算術友好”:“常規”哈希不再比傳統的算術哈希更有效率,乘法模2 的32 次方或模2的256 次方與乘法模相比不再是一件令人頭痛的事情,等等。但這是一個複雜的話題。當一切都以二進制形式完成時,很多事情都會改變。
我希望在未來的幾個月裡,基於二進位字段的證明技術會有更多的改進。













