

作者:Cynic Shigeru,CGV Research
利用演算法、算力與資料的力量,AI技術的進步正在重新定義資料處理和智慧決策的邊界。同時,DePIN代表了從中心化基礎設施轉向去中心化、基於區塊鏈的網路的典範轉移。
隨著世界邁向數位轉型的步伐不斷加快,AI和DePIN(去中心化實體基礎設施)已成為推動各行各業變革的基礎性技術。 AI與DePIN的融合,不僅能夠促進技術的快速迭代和應用廣泛化,還將開啟更為安全、透明和高效的服務模式,為全球經濟帶來深遠的變革。
DePIN:去中心化脫虛向實,數位經濟中流砥柱
DePIN,是去中心化實體基礎設施(Decentralized Physical Infrastructure)的縮寫。從狹義上說,DePIN主要指由分散式帳本技術支撐的傳統實體基礎設施的分散式網絡,例如電力網路、通訊網路、定位網路等。從廣義來說,所有由實體設備支撐的分散式網路都可以稱之為DePIN,例如儲存網路、運算網路。
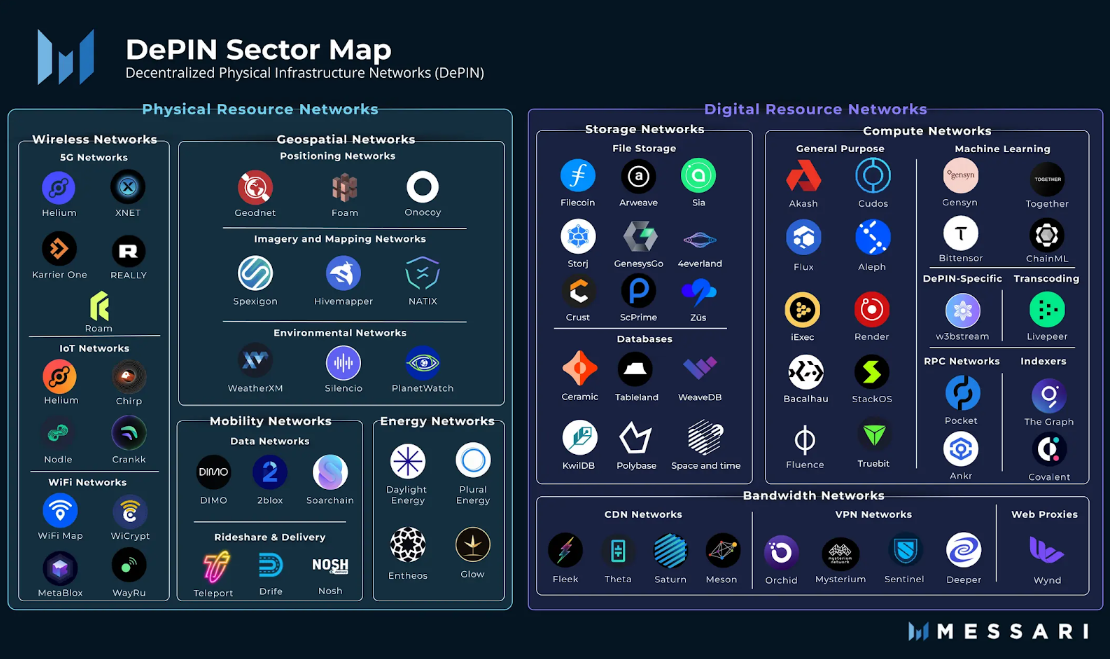
from: Messari
如果說Crypto在金融層面帶來了去中心化的變革,那麼DePIN就是實體經濟中的去中心化方案。可以說,PoW礦機,就是一種DePIN。從第一天起,DePIN就是Web3的核心支柱。
AI三要素-演算法、算力、數據,DePIN獨佔其二
人工智慧的發展通常被認為依賴三個關鍵的要素:演算法、算力和數據。演算法指驅動AI系統的數學模型和程式邏輯,算力指執行這些演算法所需的運算資源,資料是訓練和最佳化AI模型的基礎。

三要素中哪個最重要? chatGPT出現之前人們通常認為是演算法,不然學術會議、期刊論文也不會被一篇又一篇的演算法微調所填滿。但當chatGPT與支撐其智慧的大語言模型LLM亮相之後,人們開始意識到後兩者的重要性。海量的算力是模型得以誕生的前提,資料品質和多樣性對於建立健壯和高效的AI系統至關重要,相比之下,對於演算法的要求不再如往常精益求精。
在大模型時代,AI從精雕細琢變成大力飛磚,對算力與數據的需求與日俱增,而DePIN恰好能夠提供。代幣激勵撬動長尾市場,海量的消費級算力與儲存將成為大模型提供最好的養分。
AI的去中心化不是可選項,而是必選項
當然有人會問,算力和數據,在AWS的機房中都有,而且在穩定性、使用體驗方面都勝過DePIN,為什麼要選擇DePIN而不是中心化的服務?
這種說法自然有其道理,畢竟縱觀當下,幾乎所有大模型都是由大型的互聯網企業直接或間接開發的,chatGPT的背後是微軟,Gemini的背後是谷歌,中國的互聯網大廠幾乎人手一個大模型。為何?因為只有大型的網路企業擁有足夠的優質數據與雄厚財力支撐的算力。但這是不對的,人們已經不想再被網路巨頭操縱一切。
一方面,中心化的AI具備資料隱私和安全風險,可能受到審查與控制;另一方面,網路巨頭製造的AI會使人們進一步加強依賴性,並且導致市場集中化,提高創新壁壘。

從: https://www.gensyn.ai/
人類不應該需要一個AI紀元的馬丁路德了,人們應該有權利直接和神對話。
商業角度看DePIN:降本增效是關鍵
就算拋開去中心化與中心化的價值觀之爭,從商業角度來看,將DePIN用於AI仍然有其可取之處。
首先,我們需要清楚地認識到,儘管網路巨頭手中掌握了大量的高階顯示卡資源,散入民間的消費級顯示卡組合起來也能構成非常可觀的算力網絡,也就是算力的長尾效應。這類消費級顯示卡,閒置率其實是非常高的。只要DePIN給到的激勵能超過電費,用戶就有動力為網路貢獻算力。同時,所有實體設施都由使用者本身所管理,DePIN網路無需負擔中心化供應商無法避免的營運成本,只需專注於協議設計本身。
對於資料而言,DePIN網路透過邊緣運算等方式,能夠釋放潛在資料的可用性,並降低傳輸成本。同時,多數分散式儲存網路而言具備自動去重功能,減少了AI訓練資料清洗的工作。
最後,DePIN所帶來的Crypto經濟學增強了系統的容錯空間,可望實現提供者、消費者、平台三贏的局面。
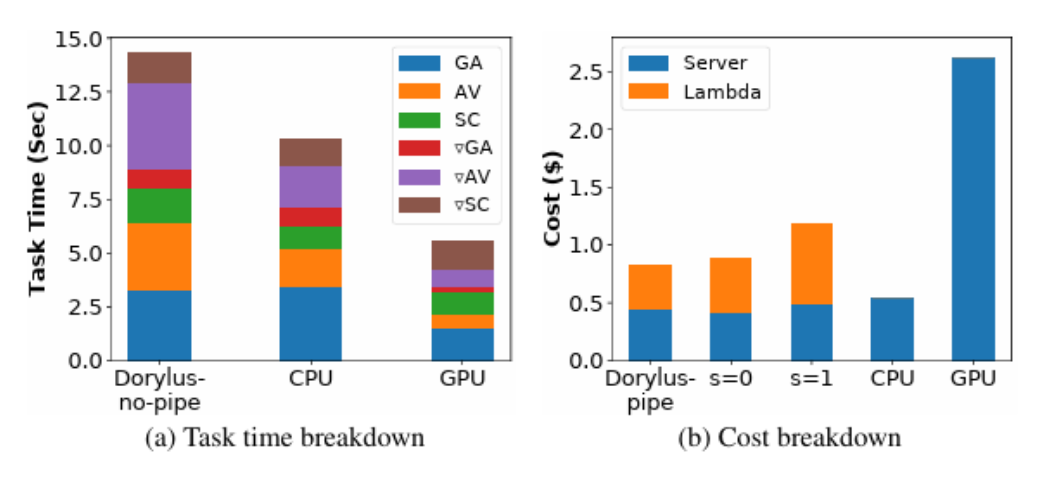
from: UCLA
以防你不相信,UCLA最新的研究表明相同成本下使用去中心化計算相比傳統GPU集群實現了2.75倍的性能,具體來說,快了1.22倍且便宜4.83倍。
篳路維艱:AIxDePIN會遇到哪些挑戰?
We choose to go to the moon in this decade and do the other things, not because they are easy, but because they are hard.
——John Fitzgerald Kennedy
運用DePIN的分散式儲存與分散式運算無信任地建構人工智慧模型仍具備許多挑戰。
工作驗證
從本質上,計算深度學習模型與PoW挖礦都是通用計算,最底層都是閘電路之間的訊號變化。宏觀而言,PoW挖礦是“無用的計算”,通過無數的隨機數生成與哈希函數計算試圖得出前綴有n個0的哈希值;而深度學習計算是“有用的計算”,通過前向推導與反向推導計算出深度學習中每層的參數值,從而建立一個高效的AI模型。
事實是,PoW挖礦這類「無用的計算」使用了雜湊函數,由原像計算像很容易,由像計算原像很難,所以任何人都能輕易、快速地驗證計算的有效性;而對於深度學習模型的計算,由於層級化的結構,每層的輸出都作為後一層的輸入,因此驗證計算的有效性需要執行先前的所有工作,無法簡單有效地進行驗證。
from: AWS
工作驗證是非常關鍵的,否則,計算的提供者完全可以不進行計算,而提交一個隨機產生的結果。
有一類想法是讓不同的伺服器執行相同計算任務,透過重複執行並檢驗是否相同來驗證工作的有效性。然而,絕大多數模型計算是非確定性的,即使在完全相同的計算環境下也無法復現相同結果,只能在統計意義上實現相似。另外,重複計算會導致成本的快速上升,這與DePIN降本增效的關鍵目標不符。
另一類想法是Optimistic機制,先樂觀地相信結果是經過有效計算的,同時允許任何人對計算結果進行檢驗,如果發現有錯誤,可以提交一個Fraud Proof,協議對欺詐者進行罰沒,並對舉報者給予獎勵。
平行化
先前提到,DePIN撬動的主要是長尾的消費級算力市場,也就注定了單一設備所能提供的算力比較有限。對於大型AI模型而言,在單一裝置上進行訓練的時間會非常長,必須透過並行化的手段來縮短訓練所需時間。
深度學習訓練的平行化主要的困難在於前後任務之間的依賴性,這種依賴關係會導致並行化難以實現。
目前,深度學習訓練的平行化主要分為資料並行與模型並行。
資料並行是指將資料分佈在多台機器上,每台機器都保存一個模型的全部參數,使用本地的資料進行訓練,最後對各個機器的參數進行聚合。資料並行在資料量大時效果好,但需要同步通訊來聚合參數。
模型並行是當模型大小太大無法放入單一機器時,可以將模型分割在多台機器上,每台機器保存模型的一部分參數。前向和反向傳播時需要不同機器之間通訊。模型並行在模型很大時有優勢,但前後向傳播時的通訊開銷大。
對於不同層之間的梯度訊息,又可以分為同步更新與非同步更新。同步更新簡單直接,但是會增加等待時間;非同步更新演算法等待時間短,但會引入穩定性問題。
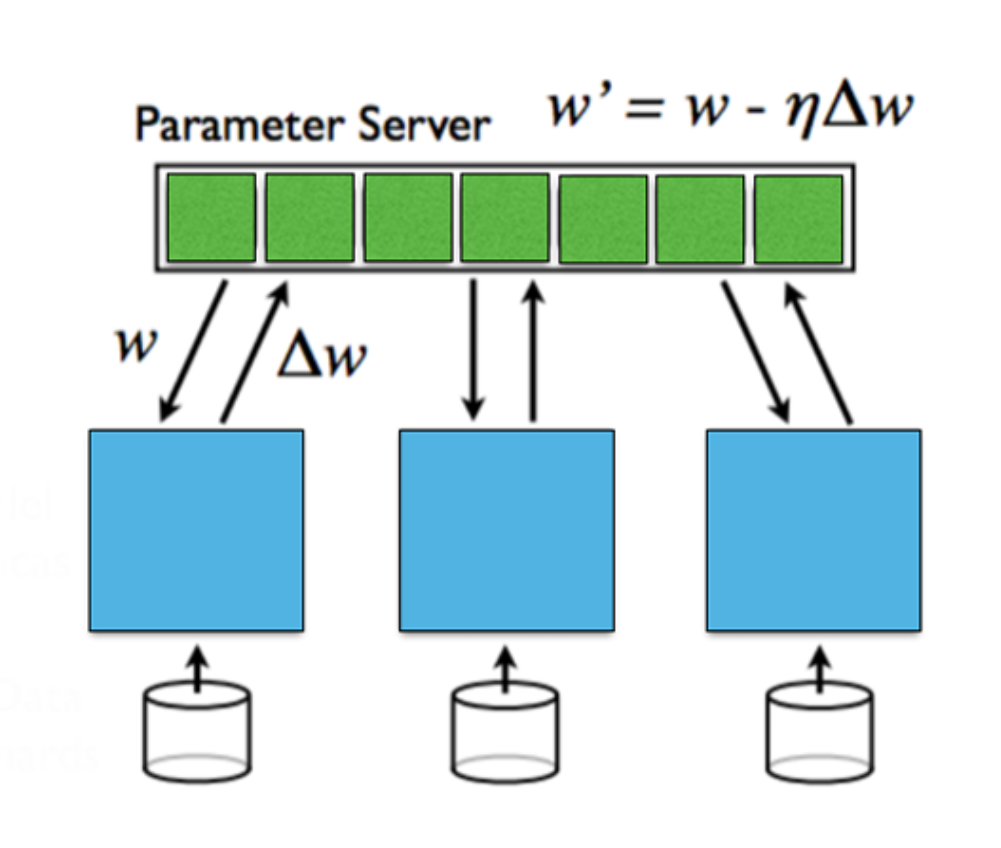
from: Stanford University, Parallel and Distributed Deep Learning
隱私
全球正掀起保護個人隱私的思潮,各國政府都在加強對個人資料隱私安全的保護。儘管AI大量使用公開資料集,真正將不同AI模型區分開的還是各企業專有的使用者資料。
如何在訓練過程中得到專有資料的好處同時不暴露隱私?如何保證建構的AI模型參數不洩漏?
這是隱私的兩個方面,資料隱私與模型隱私。資料隱私保護的是用戶,而模型隱私保護的是建構模型的組織。在目前的情況下,資料隱私比模型隱私重要得多。
多種方案正在嘗試解決隱私的問題。聯邦學習透過在資料的源頭進行訓練,將資料留在本地,而模型參數進行傳輸,來保障資料隱私;而零知識證明可能會成為後起之秀。
案例分析:市場上有哪些優質項目?
Gensyn
Gensyn是一個分散式運算網絡,用於訓練AI 模型。該網路使用基於Polkadot的一層區塊鏈來驗證深度學習任務是否已正確執行,並透過命令觸發支付。成立於2020年,2023年6月揭露一筆4,300萬美元的A輪融資,a16z領投。
Gensyn使用基於梯度的最佳化過程的元資料來建立所執行工作的證書,並由多粒度、基於圖形的精確協議和交叉評估器一致執行,以允許重新運行驗證工作並比較一致性,並最終由鏈本身確認,來確保計算的有效性。為了進一步加強工作驗證的可靠性,Gensyn引入質押來創造激勵。
系統中有四類參與者:提交者、解題者、驗證者、檢舉者。
提交者是系統的終端用戶,提供將要計算的任務,並為已完成的工作單元付費。
求解器是系統的主要工作者,執行模型訓練並產生證明以供驗證者檢查。
驗證器是將非確定性訓練過程與確定性線性計算聯繫起來的關鍵,複製部分求解器證明並將距離與預期閾值進行比較。
舉報人是最後一道防線,檢查驗證者的工作並提出挑戰,挑戰通過後獲得獎勵。
求解者需進行質押,檢舉者檢驗解算者的工作,如發現作惡,進行挑戰,挑戰透過後求解者質押的代幣被罰沒,檢舉者獲得獎賞。
根據Gensyn的預測,該方案可望將訓練成本降至中心化供應商的1/5。
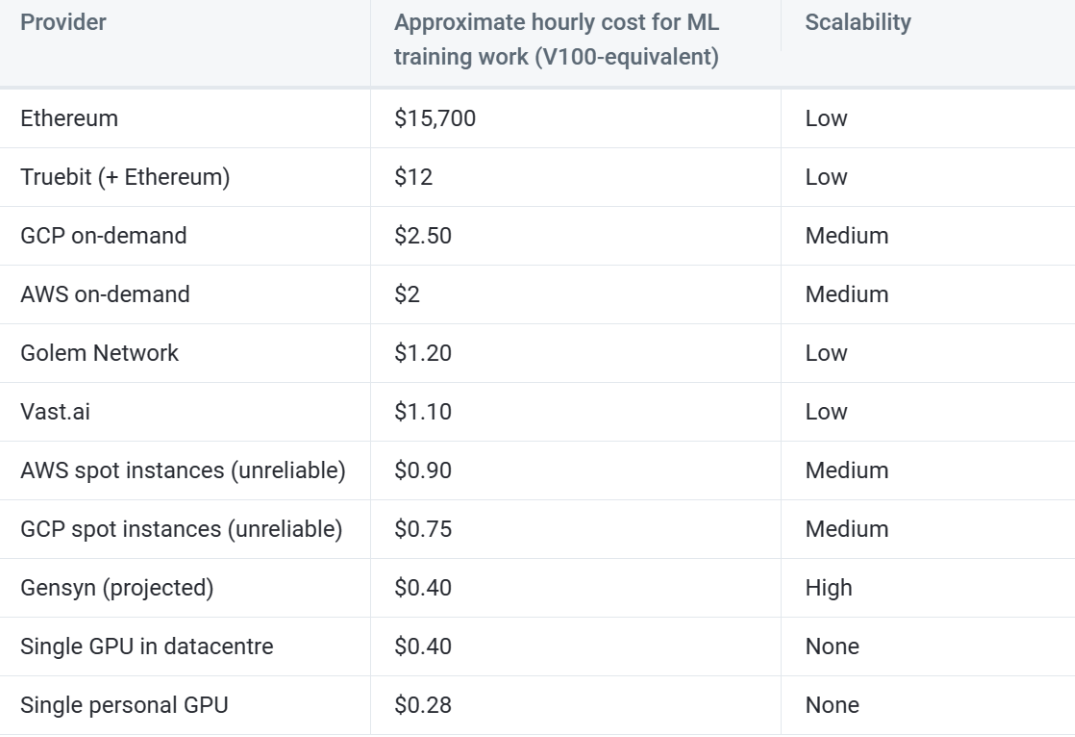
from: Gensyn
FedML
FedML 是一個去中心化協作的機器學習平台,用於在任何地方以任何規模進行去中心化和協作式AI。更具體地說,FedML 提供了一個MLOps 生態系統,可以訓練、部署、監控和持續改進機器學習模型,同時以保護隱私的方式在組合資料、模型和運算資源上進行協作。成立於2022年,FedML於2023年3月揭露600萬美元的種子輪融資。
FedML由FedML-API和FedML-core兩個關鍵元件所構成,分別代表高階API和底層API。
FedML-core包含分散式通訊和模型訓練兩個獨立的模組。通訊模組負責不同工作者/客戶端之間的底層通信,基於MPI;模型訓練模組基於PyTorch。
FedML-API建立在FedML-core之上。借助FedML-core,可以透過採用面向客戶端的程式介面輕鬆實現新的分散式演算法。
FedML團隊最新的工作中證明,使用FedML Nexus AI在消費級GPU RTX 4090上進行AI模型推理,比A100便宜20倍,快1.88倍。
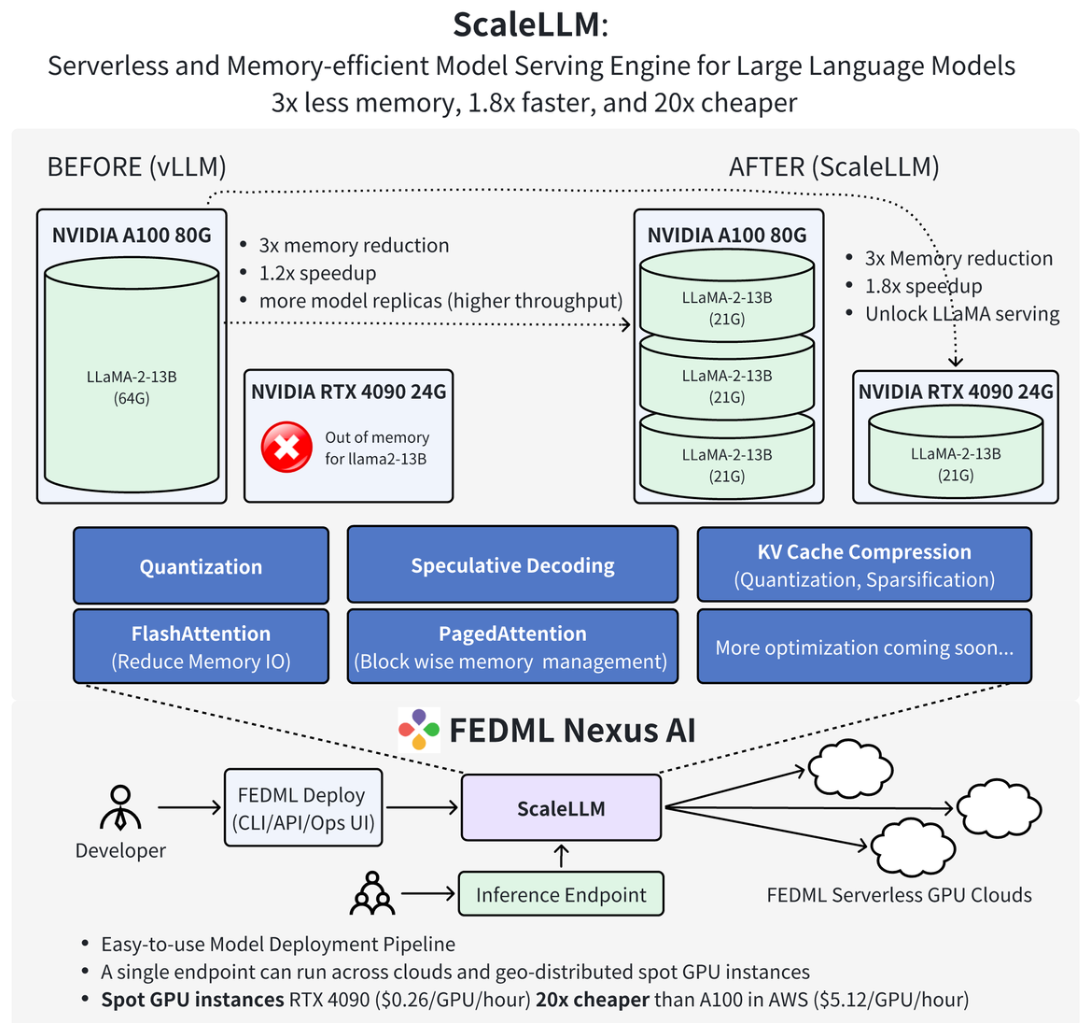
from: FedML
未來展望:DePIN帶來AI的民主化
有朝一日,AI進一步發展為AGI,彼時算力將成為事實上的通用貨幣,DePIN使得這個過程提前發生。
AI和DePIN的融合開啟了一個嶄新的技術增長點,為人工智慧的發展提供了巨大的機會。 DePIN為AI提供了海量的分佈式算力和數據,有助於訓練更大規模的模型,實現更強的智能。同時,DePIN也使AI朝向更開放、安全、可靠的方向發展,減少對單一中心化基礎設施的依賴。
展望未來,AI和DePIN將持續協同發展。分散式網路將為訓練超大模型提供強大基礎,這些模型又將在DePIN的應用中發揮重要作用。在保護隱私和安全的同時,AI也將協助DePIN網路協定和演算法的最佳化。我們期待AI和DePIN帶來更有效率、更公平、更可信的數位世界。














