图片来源:由无界AI生成
作者|马慧
前景和覆灭同时存在,数据标注从业者代延从未如此矛盾。
30岁的内蒙古人代延在今年初创业,组建了一个近30人的线上标注团队。此前代延曾在数据标注的众包平台做了两年。可以称为是“熟工”的他,对眼下的局面既期待又紧张。
他从年初就关注到ChatGPT。从AI企业注册量的粗暴增长上,代延看到了AI的行业爆火与数据标注的创业机会。天眼查数据显示,仅今年一季度就新增注册17万家人工智能相关企业,目前总计已有267万家。
他想象着自己能跟随行业共进,公司未来能发展到100人的规模。但眼下的现状却难以支撑他的期盼:数据标注的圈子很快被冲破——大量标注需求、标注工人和中间商一同涌入,单价更低了。
就像工程队接触不到有建筑需求的甲方,只能从承包方手上接项目一样,代延接触的工价因项目层层转手越压越低。他拒绝干一天只能拿到30元的标注项目。
与此同时,代延还面临着标注业没有职业晋升、没有合同保障、被拖款也投诉无门的窘迫。他自嘲:“我们就是新时代的数据民工。”
但这并不是问题的全部。更大的问题在于,自动化标注也正在吞噬他们手上仅有的项目。由代延这样的数据标注员训练的AI,正在人类监督中自我学习,进行自标注。
自动化标注将极大减少企业成本,也成为数据标注市场上最被看好的方向。
代延不得不为“AI可能完全取代人”做准备。他带着团队同时做文本标注类别的教辅标注和3D点云标注项目。一个是文字,一个是图片视频。代延做好了一个项目如果被AI颠覆,就立马带着团队转型去另一个领域的打算。
此外,团队人数也要精简。代延划掉了脑海中想象的百人公司规模。他认为最终或许只会保留20人的熟手团队。
这些由数据标注员一手训练的AI,一边让他们梦想着赚得更多,同时逼着他们做好被颠覆的打算。
为了让机器像人一样理解文字、语音、图片,人类创造了一个机器的学习链条:采集物理世界的实物图像和声音,对数据进行标注、清洗,将数据转换为一串串代码后输送给机器。
AI学者认为,三岁婴儿通过眼睛“拍摄”了数亿张图片,反复认识世界。所以只要给机器灌输足够多的数据,也能让机器从学会识字、认句子,最终理解语言背后的深意。
标注图集ImageNet上有1500万张图片,这个数据集帮助无数AI企业获得在计算机视觉上的突破,比如人脸识别、搜图看看。
为了搭建ImageNet,全球167个国家的近5万名数据标注工一起标注了两年半,他们都来自众包平台Mechanical Turk。
标注要求十分简单,MTurk常见的工作内容就是区分照片的颜色,或者对图像中出现的动物进行分类,或是用一个个方框框定选定对象,标注其名称:这是蛋糕、这是汽车、这是一朵云等等。

图:整数智能
该平台上的20万名零工分布在人力成本低廉的非洲和东南亚,甚至形成了特色「数据标注村」。他们标记的数据支撑着科技企业在AI上的探索。
而中国的上百万名标注员分布在贵州、山西、山东、河南等省份的二三线城市,并逐步向人力成本更低的县城渗透。他们或是依赖线上众包平台,或是加入线下的数据标注公司和标注基地。
标注内容根据场景区分为文本、图像和语音,对应着帮助机器获得识字、识图和听声音的功能。
早期的标注项目集中在互联网企业,主要标注语音和文本。现在则转向自动驾驶企业标注由激光雷达扫描获得的3D场景,比如点云标注;或是更垂直的文本和语音标注方向:帮助教育公司的大模型提供教辅类标注数据;或是为医疗机构的大模型提供校对后的医疗数据。
当AI迈入2.0时代,ChatGPT惊艳了投资者、企业家和创业者,大家对AI的期待已经不仅仅是死板地识别文本、语音和图片的信息了。人们还希望AI能像人一样真正理解事物之间的联系,识别微小的区别和动作背后的情绪,主动地分辨和搜集信息。
比如让自动驾驶汽车区分前方是一个空扁的塑料袋,而不是一块颜色体积相近的石头;让游泳池旁的摄像头不再只是记录泳池旁发生了什么,而是理解发生了什么,在有人溺水时发出警报。
这些依然需要依赖数据标注,并且对标注提出更高的要求——更垂直、更精确、更节约。
标注市场的热潮也由此开始。
很难有数据直接说明新的标注需求激增,但这并不难判断。因为仅2023年一季度,中国就新增了17万家人工智能企业,而只要是用到AI的公司,就势必有数据标注的需求。
需求很快传导至数据标注市场。在数据标注从业者聚集的贴吧内,一天能刷新出十几条项目招人的帖子,包括且不限于文本标注、录题审核、无人机售卖视频标注、2D检测杆、3D点云等从文本到图片视频的标注项目。
一位从业多年的数据标注工作者察觉到,今年的无人车标注项目有所增加,而由AI2.0热催生的垂直领域大模型创业,让原本没落的文本标注项目细分至不同赛道,也增加了小众的数据标注的需求。
在需求的推动下,成立新团队淘金的不止代延。山东东营的张唯在去年底也开始投身数据标注创业,半年发展为一个十几人的小团队。依靠当地政府的补贴和扶持,张唯的公司不仅获得免费的办公室,政府还帮忙拉通甲方资源。
项目订单不少,从最初十几万的项目到最近的40万订单,紧迫的交付任务让张唯更积极地寻找标注工:前几天,张唯仅一天就添置了6台电脑。
在河南郑州,一家做数据标注的众包平台正迁移至能容纳百人的两层办公楼。它们在门口招牌、办公室里都写上公司的定位:“AI人工智能大数据研发基地”“重复的数据清洗,是为了你的AI更智能”。
“标注项目订单多到做不过来。”其负责人说。

一家数据标注公司的乔迁仪式现场
图片来源:受访对象提供
热钱也久违地进入了标注公司的口袋。数据标注龙头海天瑞声,在今年的3~5月股价最高涨了4倍。
根据36氪消息,今年以来B轮及以前的十余家数据标注平台,集体迎来了接近100%增幅的高估值。从去年下半年开始,自动标注公司陆续获得新融资。
2022年9月,博登智能获得千万元融资;12月,星尘数据完成A轮融资5000万元,相距上一次2018年6月获得融资已经时隔4年半。
2023年4月,数据标注解决方案公司「恺望数据」获得新一轮战略融资;6月,AI数据公司「整数智能」获得数千万Pre A轮融资。
他们斗志昂扬地打出替代人工标注的口号:“重构数据标签生产”“自动化产线+规模化人力”“打破自动驾驶标注的手工模式”。
显然,资本市场也正重新关注这个新兴领域。
数据标注的链条由三部分组成。
上游:1~150人的数据标注公司、线上散兵和小作坊。
中游:数据服务商,一类是承接上下游的中介方众包平台,一类是企业为稳定投入产业而选择自建标注基地。
下游:科技公司、行业企业、AI公司、科研单位,在2018年左右以互联网企业为主导,现在转至车企、自动驾驶企业。
行业普遍采取分包模式,即先由甲方企业发标,第三方服务商参与竞标,竞标成功后进入企业的供应商梯队,其中核心供应商能享受优先任务选择权和更多订单。
企业对核心供应商的要求是拥有至少30人的交付团队,成熟的订单交付经验,建立培训体系、把控交付质量和数量的能力。稳定的生产团队,最终导向让公司更有竞争力的低报价。
然而,管控团队带来的低价优势已然被打乱。“今年竞标惨烈!”一位服务商告诉「甲子光年」,“一个项目我们报200元,有人报80元一天。”
最终项目由报价低的团队拿下,最后却回到更成熟的团队手上。“他们完不成又被甲方转回给我们,但价格已经上不去了。”
由于代延的线上团队不直接接触甲方。所以市面上多级分包层层压价的混乱局面,让他们倍感压力。
数据标注是资源型行业,谁能拿到和甲方的合作谁就有优势。代延透露,一些个体注册公司后,谎称有40-50人的专业团队,以极低的价格参与投标,拿下项目后,拆分成4-5份分给不同的团队,小团队再往下分,层层抽佣,中间商赚到差价,分给数据标注工的计件价越来越低。
只要有人接盘,就会一直螺旋向下。
「甲子光年」得到的一份价格表显示,从2D标注到3D激光点云标注,标注项目单价一般为0.5~1.5元/框。代延曾接到过打了对折的单框价,“至少转过四五手了”。
单价内卷直接导致标注人员的薪资缩水。代延和团队属于半全职状态,团队成员多为宝妈、大学生、自由职业者和职高学生,每天拉框6小时。保持着这样的状态,代延在2022年疫情期间,每月有4~5千元的收入。
“有电脑、有电就能操作”,这是数据标注招人贴中常见的吸引人入行的话。过去,这一度是数据标注行业最显著的优势。但今天这种优势却让整个行业陷入内卷。现在代延每月收入只有2~3千元。
虽然收入降低,但工作量并没有下降。恰恰相反,数据标注的工作更加复杂与细致。
数据标注的资深从业者们更怀念互联网时期的标注市场:单框价格高3倍,项目量大。一个60~70人的团队,能拿到月入30万的业绩。“现在市场上都是产值(单人每天标注产生的价值)不到百元的项目,以前一天大几百。”一位从业者说。
那时的项目操作简单且没有要求,比如给无人车做2D场景标注,对图片中的车辆拉框时,只要能框住就行,没有要求。
但现在不同,“贴合度”是甲方最看重的验收标准。“去年还要求误差在5~7毫米,今年就要3~5毫米了。误差要求越来越小。”代延说。
人工智能学者吴恩达多次强调,有标注的高质量数据才能释放人工智能的价值,高质量数据越多,人工智能的发展就会越快。
在无人车的标注数据中,表现为矩形框与标注对象的贴合度,贴合度越高算法精度越高,算法对车辆的控制越精准。
高质量的文本标注项目,表现为语义理解的正确性、答题的正确率等。正确率越高,被训练的大模型越聪明。
熟手才能保证数据交付又快又好。代延曾经让一个新手参与核验ChatGPT做完的数学题是否完整、逻辑是否正确、语言能否被小学生理解。新手标注的7500个数据因正确率太低,被甲方要求返工,代延和同事花了十几天才纠正完。
数据标注越来越不是一个没门槛的活。复杂的语音标注,医疗、法律、金融等专业数据集标注生产,更需要有学科知识储备的专业人才做专业标注。
代延认为,以无人车项目为例,新人成为2D标注熟手需要做3个月,成为3D熟手需要练习4~6个月。
这种练习是指,训练拉框的精确度,用鼠标在电脑的标注页面一气呵成拉出一个矩形框,能准确盖住标注对象,不踩线、不漏点,甚至是严丝合缝。
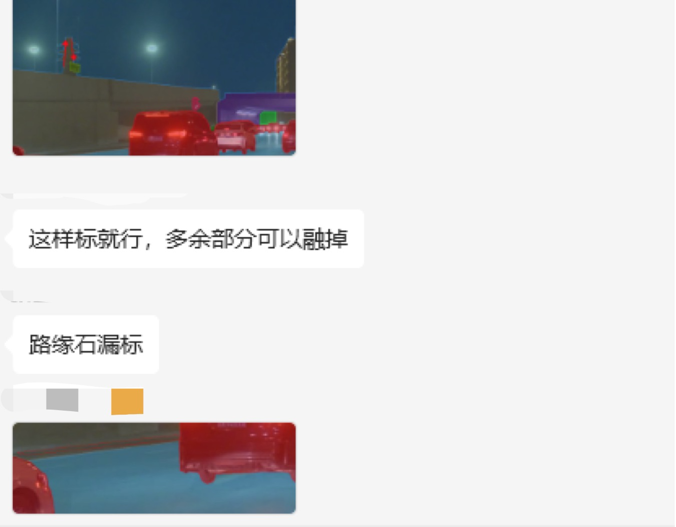
图:数据标注熟手指出标注中的问题
只是,当机器开始自学,替代人为机器做标注,人们花费时间训练的技能还有意义吗?
代延意识到AI在靠近,是从前段时间做的图片标注项目中。
这是一个代延做了两年的老项目——识图。数据标注工需要识别图片中的文字并打印出来,价格是8毛/张。代延标注的数据,被喂入了识图模型中。现在,这一模型已经熟练地识别图片中的文字。代延的标注工作开始被缩减为订正和审核。难度下降了,标注单价也下跌了。
被人类用标注训练的AI,正在替代人力的标注工作。在苏黎世大学的调查报告中,研究人员通过实测发现,ChatGPT在15项标注任务中的处理能力高于众包人员。大模型嵌入众包平台的进度条也被拉快了。洛桑联邦理工学院之后的研究发现,已有超过30%的众包标注者在处理文本标注时使用了大模型。
AI无疑比人工更省时省力:研究人员表示,ChatGPT的单位成本只相当于MTurk的1/20。
代延也做好了这条业务线随时会被“更完善的AI”取代的准备。他把未来押宝在更有技能要求的自动驾驶标注中。
但自动驾驶标注也正被AI侵入。相比人工的拉框方式,自动化标注只需要内置大模型,进行参数设置后,原本需要手动标注的矩形框会自动生成。目前唯一的问题是,生成的矩形框有踩线、贴合度太低等质量问题,需要人工逐一检验。
效率的提升让车企惊喜。理想在使用大模型2.0进行自动化标定,效率是人的1000倍;特斯拉一直在积极推进自动标注的进展,比如在2022年6月裁撤了200名为特斯拉标注视频,以改进辅助系统的美国员工,因为特斯拉的自动标注能力大幅改善,标注10000个不到60秒的视频,只需要大模型运行一周,而不再需要人工标注几个月。
AI数据公司整数智能的创始人林群书说,越来越多的车企和AIGC企业采用大模型产品做自动化标注,营收正在大幅增长。他们最新的动作是在新加坡建立研发分部。
但对于自动化标注的增长,第三方服务商没那么乐观。河南一家众包平台的项目经理说,自动化标注还不能取代60%以上的标注需求,只能作为辅助标注工具,处理单一或特定数据,提升人效。
另一家数据标注公司的产品经理认为,自动标注只能过滤简单的基础数据,还不能像人一样从复杂有争议的场景中精确识别物体。这也是数据标注市场,如今依然是以自动驾驶标注数据为主导的原因。
不过大家也认同,未来的数据标注将从重人力转向重技术的趋势。
总之,不是被同行“卷死”,就是被技术“卷死”。但坐以待毙肯定不行,数据标注的第三方公司在寻找未来的出路。
代延的计划是紧跟市场,保持警惕,随时裁员,同时向做自动化标注工具的方向发展。一家众包平台的创始人在和同行交流时说,未来不能堆人力,要有研发能力。
对于个人呢?行业里流传的职场路径是,新手标注工——熟手标注工——标注项目管理员/经理——甲方公司数据分析师,最终实现月薪上万的晋升。
代延认识的数据标注工没人在朝这个方向走,他们要么停留在原地,要么退出,最好的情况是建立自己的标注团队,像代延这样,不过他也没有觉得更轻松。
一边是AI风口带来的项目需求增长,一边是更混乱的竞价、更低的人均产值和正迅速成长的AI。两种情绪是交织的,AI会带来无限机遇,AI也会淘汰“我们”。
巴比特园区开放合作啦!



中文推特:https://twitter.com/8BTC_OFFICIAL