

Turbo-Geth
Turbo-Geth 作為一個純粹出於好奇心的項目,始於2017 年(沒錯,就是在CryptoKitties 導致的瘋狂擁堵時期)。一開始是為了探究基於trie 的數據庫模式的替代方案。在2018 年3 月,Turbo-Geth 項目從以太坊基金會處獲得了一筆小額的獎金(2.5 萬美元)。在2019 年第一第二季度,Turbo-Geth 被用作狀態租金(State Rent)研究的狀態分析平台。到了2019 年第三第四季度,Turbo-Geth 也被用於執行無狀態以太坊的回溯檢驗(back testing)。在Devcon5 舉辦以前,我認為它在概念上已經很可靠了。
在Devcon5 上,我提議在一年內不再接受EIP,好把所有的實現都轉成類似的數據模式。但因為大家有所懷疑,而且“核心開發者” 團體也沒有這個積極性,我的提議沒有被採納。
懷疑意見主要圍繞著高效計算和更新狀態根哈希的方法。在2020 年3 月的EthCC 2020 大會上,我們提出了解決方案:額外的數據結構,叫做“中間哈希值(Intermediate Hashes)”。接下來幾個月裡我們就完全實現了這個方案。
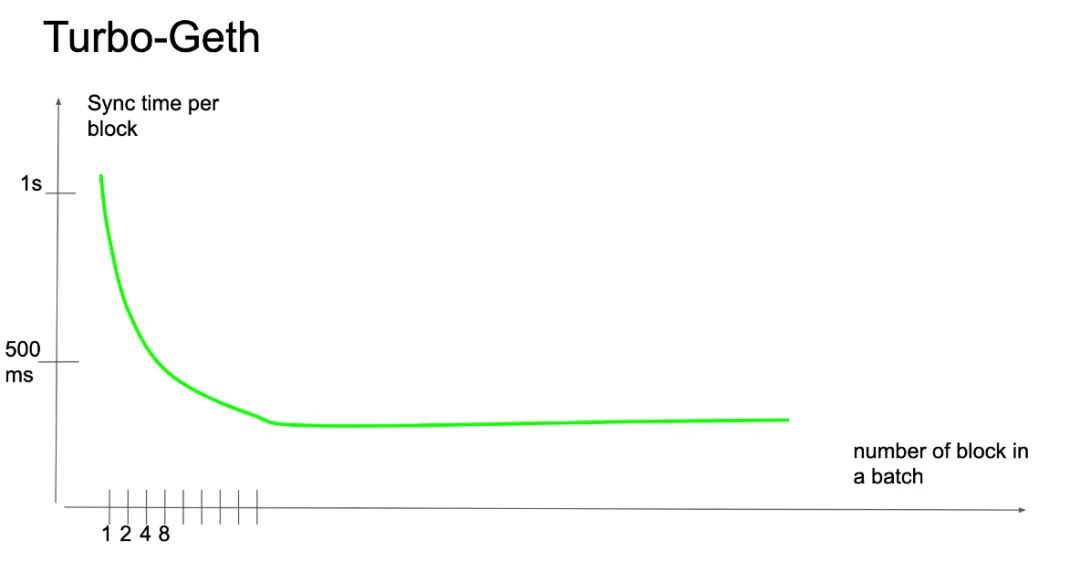
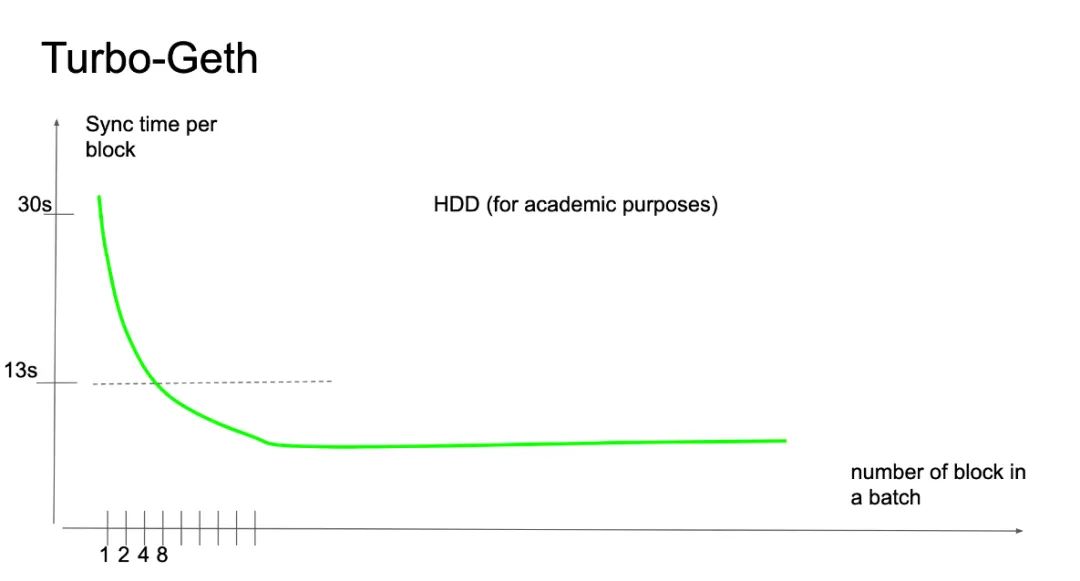
階段式同步(staged sync)的想法來自於對按表寫入變更量(per-table write churn)的測量值的觀察。對數據變更(churn)的解決的方案是在一個預先排序號的序列中插入數據。我們在2019 年末仔細觀察了這些現象,但我們的第一個實驗性的實現在2020 年2 月才表現出有重大的性能優勢。
階段式同步在架構層面上是一個非常重大的改變(但沒有大改數據模式),我們在2020 年3 月至7 月實現了這一功能。正是有了它,我們才能大幅(10 倍)壓縮同步時間。
在2020 年8 月,我們又發現了將狀態表示數據從50 GB 縮減到10 GB 的方法。
在2020 年9 月,“中間哈希值” 功能的粒度做得更細,將計算狀態根哈希的速度提升了4 倍(從200 ms 縮減到50 ms),同時將其數據規模從7 GB減小到了2.5 GB.
當前我們正在開發合適的日誌索引(indexing of logs)
那麼,這一切到底意味著什麼呢?
其實,這都不意味著什麼,因為當前的實現還沒有到達效率的極限。
還有幾個“未解之謎”:
對久遠歷史中的狀態的默克爾證明還無法高效生成(對近期歷史的默克爾證明的生成效率是沒問題的。可以通過引入中間哈希值的快照來緩解(這些數據相對來說也不大)一些共識計算無法與階段性同步協調工作,理想情況下,應該共同設計兩者
Silkworm
創建一個符合Apache 2.0 協議、用C++ 實現的模塊化以太坊實現的想法,始於2019 年初,因為那時我們看到“Aleth” 項目基本上已經被放棄了。
但那並不是一個好時機。
到了2020 年5 月~6 月,時機終於到來。出現了4 大轉機:
我們從BoltDB 切換成了LMDB(用C 語言實現的數據庫),這就能保證Turbo-Geth 和Silkworm 之間的數據庫兼容性。階段式同步模式自然而然地將實現分解成了相對獨立的組件,這些組件基本上都通過數據庫中的記錄來交互(或者說通過內存中的page 來交互,如果交互都發生在一個數據庫的事務內的話)。這就意味著,我們可以逐個逐個組件創建C++ 實現。更早的EVM 實驗(使用EVMC 接口)暴露出了使用跨語言接口的巨大開銷,而EVMC 的雙重接口又加劇了這一點。我們覺得已經有了足夠的經驗,能在一個可預期的時間內(1 年內,而不是5 到10 年)、靠著一些專家的幫助,就能完成這一切了。
未來
啟動Silkworm 項目也打開了我們的思路,比如我們可以把實現逐個逐個地遷移到其它編程語言(比如Rust)上。
我相信,以太坊1.0 即使不引入分片,也能擴展至少10 倍的吞吐量。我們主要面臨三個方面的挑戰:
區塊的Gas 上限更高會更容易招致DOS 攻擊。 Turbe-geth 的安全極限可能是其它實現的10 倍高;而Silkworm 可能會更高。更高的Gas 上限會產生(數據量)更大的區塊。這就會反過來產生兩個問題:a)區塊傳輸問題。這可以通過預先共識來處理(本質上就是犧牲交易時延來換取交易吞吐量)b)區塊下載和存儲問題。可以通過使用專門化的存儲網絡比如BitTorrent 來解決(這些工作已經在進行中)。
(完)
(文內有許多超鏈接,可點擊左下”閱讀原文“ 從EthFans 網站上獲取)
原文鏈接:
https://github.com/AlexeyAkhunov/papers/blob/master/Turbo-Geth-Silkworm.pdf
作者: Alexey Akhunov
翻譯:阿劍










